I am right now exploring the capability of openEHR for integrating patient health records across various healthcare systems and providers. I have a few questions and would love to hear your insights:
What are the prescribed procedures for implementing openEHR in a multi-system environment?
Can anyone share their experiences or case studies on successful integrations using openEHR?
What challenges should I be aware of during the integration process, and how can they be mitigated?
Welcome Steve, briefly openEHR is not a good fit for integrating a multi system environment if they all have their own data models. If this is your scenario, FHIR is a much better technology. But integrating a multi-system environment is a very expensive, time consuming, error prone strategy that can only deliver limited value that will always hit roadblocks (is at least the openEHR vision). So it’s wise to explore a scenario where you will standardise the internal data models of the applications. If this is an option for you, openEHR is by far the best choice. The recommended approach is to go use case by use case where you do one use cases entirely the openEHR way.
Happy to discuss further, it’s quite a common question, but there’s actually not that much concise answers on this forum recently. A more detailed description of your project, IT systems, environment, healthcare system etc. would be very helpful.
I don’t think it depends on how openEHR operates, but more about how tenancy will work. For instance, the integration will keep the data from different systems accessible only by the owning system or all the data in the integrated repository will be accessed from all the systems? (multi-tenancy vs. single tenant).
Then another question would be: do you want to maintain the reference to the originating system or do you want to start from scratch? openEHR has this IMPORTED_VERSION class that allows to have a reference the data in the original system, though if it wont really be used you can just create all the data as new ORIGINAL_VERSION.
Then for the integration itself, you’ll need to model your data with archetypes and templates in order to have that imported into any openEHR data repository, then do the corresponding data mappings between your original schemas and data models, into those archetypes and templates. This is very common when working with openEHR, and the most time consuming thing, though you’ll need to do the data mappings anyway even if not working with openEHR.
At one level, as others have said, integration to an openEHR CDR is no different than using any other approach. On the one side you generally have a set of disparate data structures, terminologies from source systems, and on the other you have a target set of data structures and terminologies inside the openEHR CDR.
I guess the prime decision is the extent to which you want to normalise the data on import
import the source datas structures ‘as-is’ in which case you can develop very simple clones of the source data using GENERIC_ENTRY archetypes bundled into target templates. This is an approach that @yampeku has used extensively.
That clearly involves much more mapping / transform work but should give you a much more coherent set of data. The projects I have done tend to take that approach as we are generally trying to create a new primary record, not an extract of existing records.
The final question on normalisation is how you handle aggregate data i.e similar or even duplicate data coming from source systems. Do you attempt to de-duplicate? Is that even possible without manual intervention? Is it necessary?
Either way, openEHR does make the building of those target data structures/ schema really easy, compared to traditional approaches, but, as others have said you can’t avoid the mapping complexity, even if you are lucky enough e.g. that everyone is using FHIR, because the chances are that they are using different profiles or expressions of the same profiles.
Thanks for the insight, I agree that FHIR is better for integrating diverse systems, while openEHR excels with standardized internal data models. We’ll consider your advice and evaluate our project’s specifics to choose the best approach.
Thanks for clarifying the tenancy and data referencing aspects. Modeling with archetypes and templates seems crucial for smooth integration, despite being time-consuming.
Your insights are valuable.
Normalizing data in openEHR seems crucial, balancing between simplicity and coherence. Deduplication challenges highlight the need for careful planning and manual intervention considerations.
After the openEHR SEC REST working group meeting yesterday I’d like to revive this thread. We discussed at least two use cases likely similar to the one @badsmith describes:
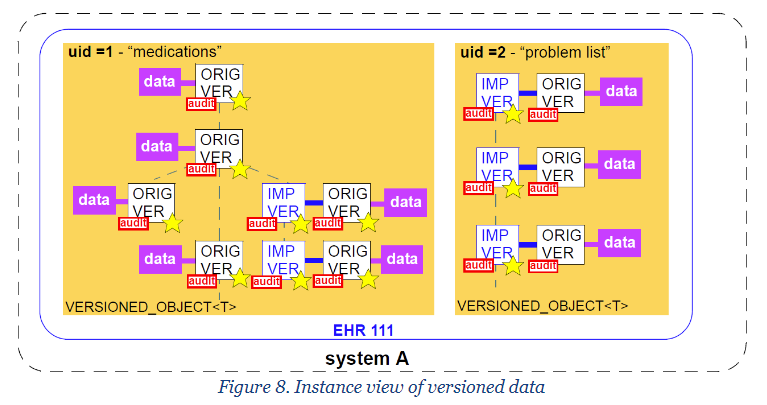
In the RCC organisatiation’s INCA system in Sweden they have an openEHR CDR where they want to aggregate openEHR Compositions replicated from several different openEHR source systems. Even for the same patient the compositions can come from different sytems with different system-IDs since cancer care in Sweden is distributed and many cancer patients get some specialized treatments at another provider than in their home region. In this use case there are links between openEHR ACTIVITY instances in INSTRUCTIONs (e.g. parts of chemotherapy medication orders) and ACTIONS (e.g. chemotherapy administrations) in the future there may be other kinds of links too. Thus it would be deisrable to keep the identities of COMPOSITIONs and other VERSIONED_OBJECTs form the source system when importing data to the national INCA CDR. This means there will be a mix of system_id in the composition identifiers. (@robahs at RCC might add more info later)
@sebastian.iancu described another use case in the Netherlands where they want to aggregate data (selected COMPOSITIONS?) from several different CDRs to a central CDR, Sebastian can describe further in a separate post.
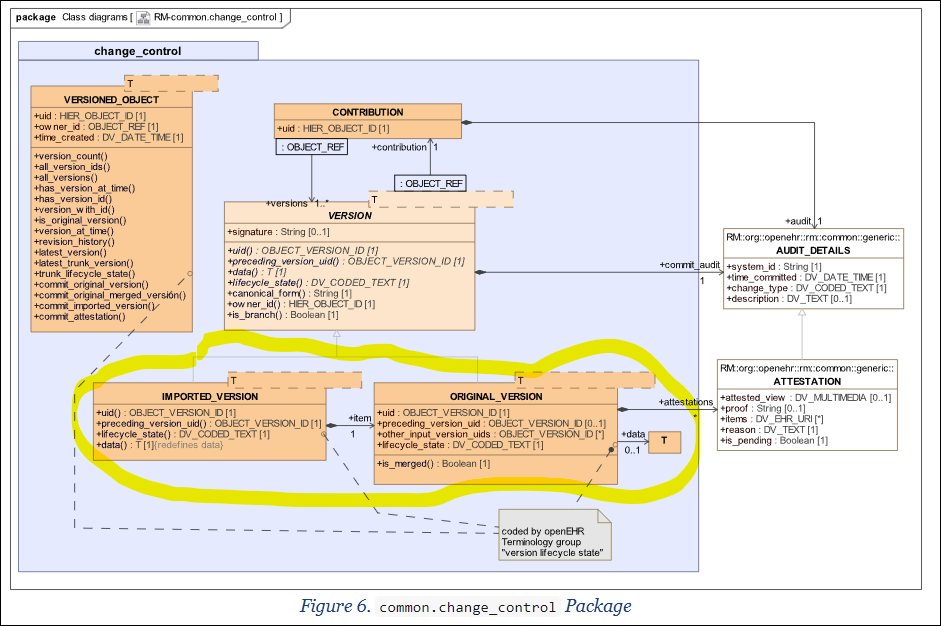
As @pablo reminds in two related threads, this is exactly what openEHR’s IMPORTED_VERSION described in e.g. chapter 6 of Common Information Model was intended for as designed by @thomas.beale and others a long time ago:
As @pablo says above, we don’t know how well supported IMPORTED_VERSION is in systems, it would be very helpful if somebody from each openEHR supplier could mention current status, previous experiences and maybe future plans about support for this, for example:
@Seref mentioned that @chunlan.ma from Ocean Health systems might have some experiences from a system that used IMPORTED_VERSION
@thomas.beale what are Graphite’s thoughts regarding this?
@Bostjan_Lah or others from Better do you support or plan to support this?
@vidi42 or @birger.haarbrandt or others from EHRbase/Vitasystems do you support or plan to support this?
Are there others that have implemented this (or plan to)?
When we know a bit more about this it would be interesting to discuss what the alternatives are regarding modifying/extending openEHR’s REST interfaces etc to accomodate for generating IMPORTED_VERSIONs when recieving COMPOSITIONs and other VERSIONED_OBJECTs from external systems that have different system-ids.
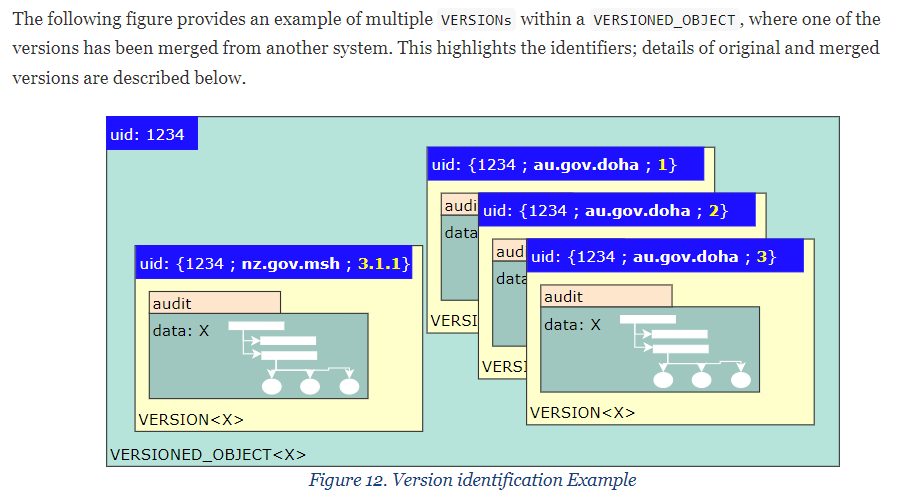
Readers not familiar with IMPORTED _VERSION etc will find things like the figures below in Common Information Model
One of our applications needs to receive and persist healthcare data from various clinical information systems and display the data in a single aggregated view. All of this healthcare data is transformed into composition instances and stored in our openEHR database.
We use the FEEDER_AUDIT_DETAILS.system_id to represent the original systems, allowing us to trace the source of each composition instance. Since we do not need to run reports on all data fields of the original data, we apply a minimal transformation approach. We keep the metadata of the original data in the compositions, and also save the original data (such as PDFs or images etc.) using “FEEDER_AUDIT.original_content” of the composition instance. This ensures that no original information is lost.
I am not sure whether our experience helps your original question or not.
There won’t be a one-size-fits-all solution for integrating healthcare data from different sources. The approach should be tailored to the specific use cases and requirements of the integration.
Hi Erik,
the scenario you describe is indeed what IMPORTED_VERSION is used for.
So far we don’t have that scenario in the US environments we are dealing with - they are more like a mega-system with one logical instance of Cerner and/or EPIC. We’ll find out whether that assumption holds up in the next few months.