The example is from the “openEHR-EHR-CLUSTER.laboratory_test_analyte.v1.0.2.opt2” template found in “COVID-19 Pneumonia Diagnosis and Treatment - 7th edition”
In my experience there are many possible values and the modeler(s) don’t want to limit the field too much. So it is left for “later”. Usually it is not constrained in the templates and goes to use as “any”.
The decision is left to a programmer who probably doesn’t understand (or care) about the clinical meaning of the field. I suspect that many such fields are implemented as free-text leaving the querying/use problems for “later”. So it would be better to model it properly in the first place.
p.s.
In my case “a programmer” is a computer program generating the form. It can generate an “any” field in just a second and be done with it. But I believe it is wrong from a UX and clinical perspective.
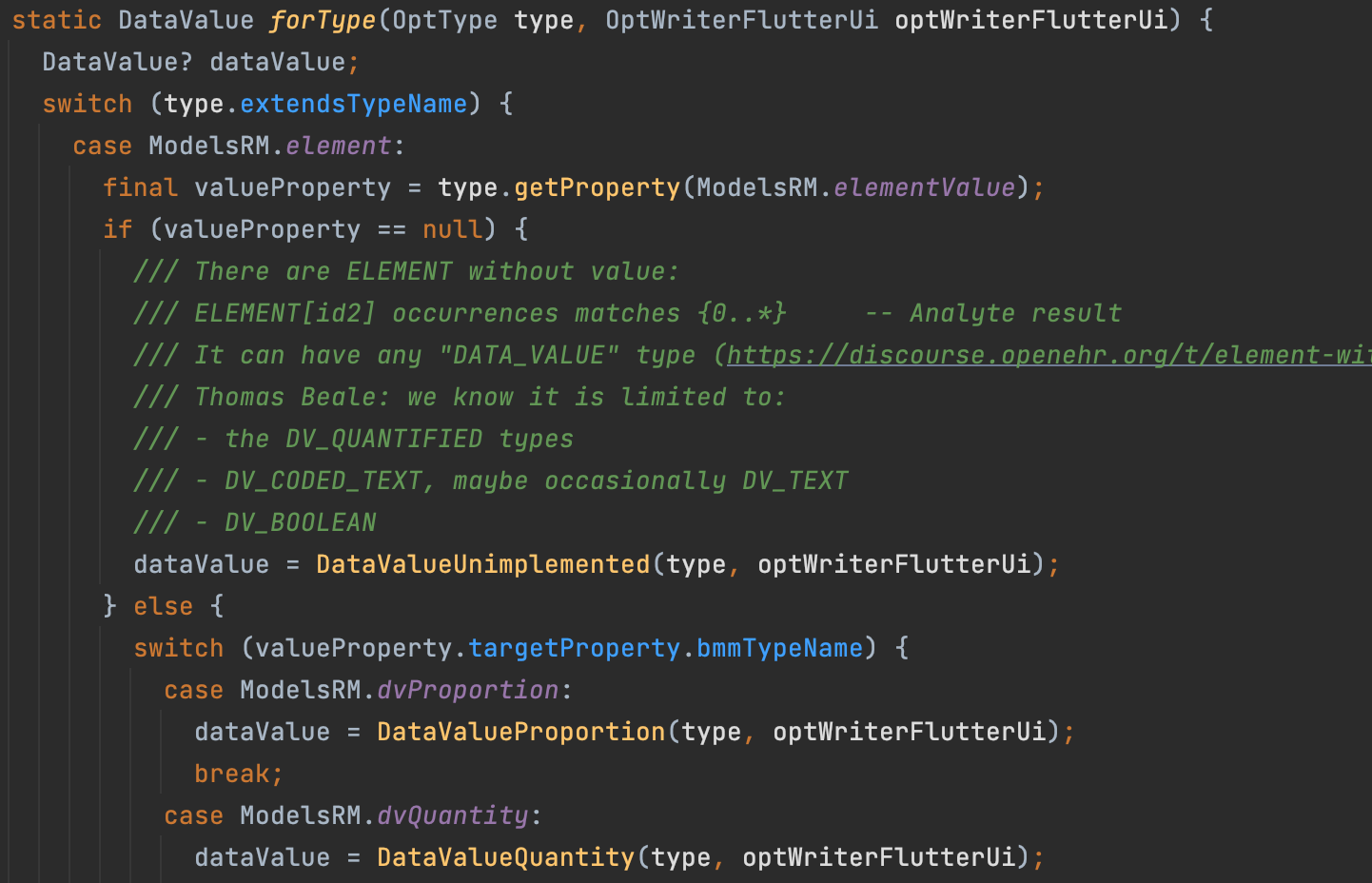
Yes, I realized it is “only” DATA_VALUE types. That is 20 types + 20 in combination with DV_INTERVAL.
So a user would get a list of 40 options before entering any data? Is this how others implement it?
I’m curious because I have to implement this
p.s.
In practice I believe that “Analyte result” could limit some of the types and not leave it to the programmers to decide.
Some types on the DATA_VALUE diagram you linked to will obviously not be used.
Any time I (in the role of a modeler - not clinical - just a database modeler) left some field left to interpretation, it was interpreted incorrectly. I always blamed myself for not being precise enough.
So the rationale for modeling labs this way, is that most lab data is acquired through lab messages where it is often impossible to know in advance, exactly what datatype will be supplied or indeed units.
So this is message driven data capture, and essentially read-only, with the datatype being resolved at run-time, so you should be able to apply the correct
If the lab data is to be entered manually (quite common in registry-type projects) then I would create a template where everything was pre-constrained.
Some progress has been made on microbiology archetypes, based on work done by Highmed but using the generic archetypes unconstrained for lab messaging, with the option of templating these locally for manual data entry is working well.