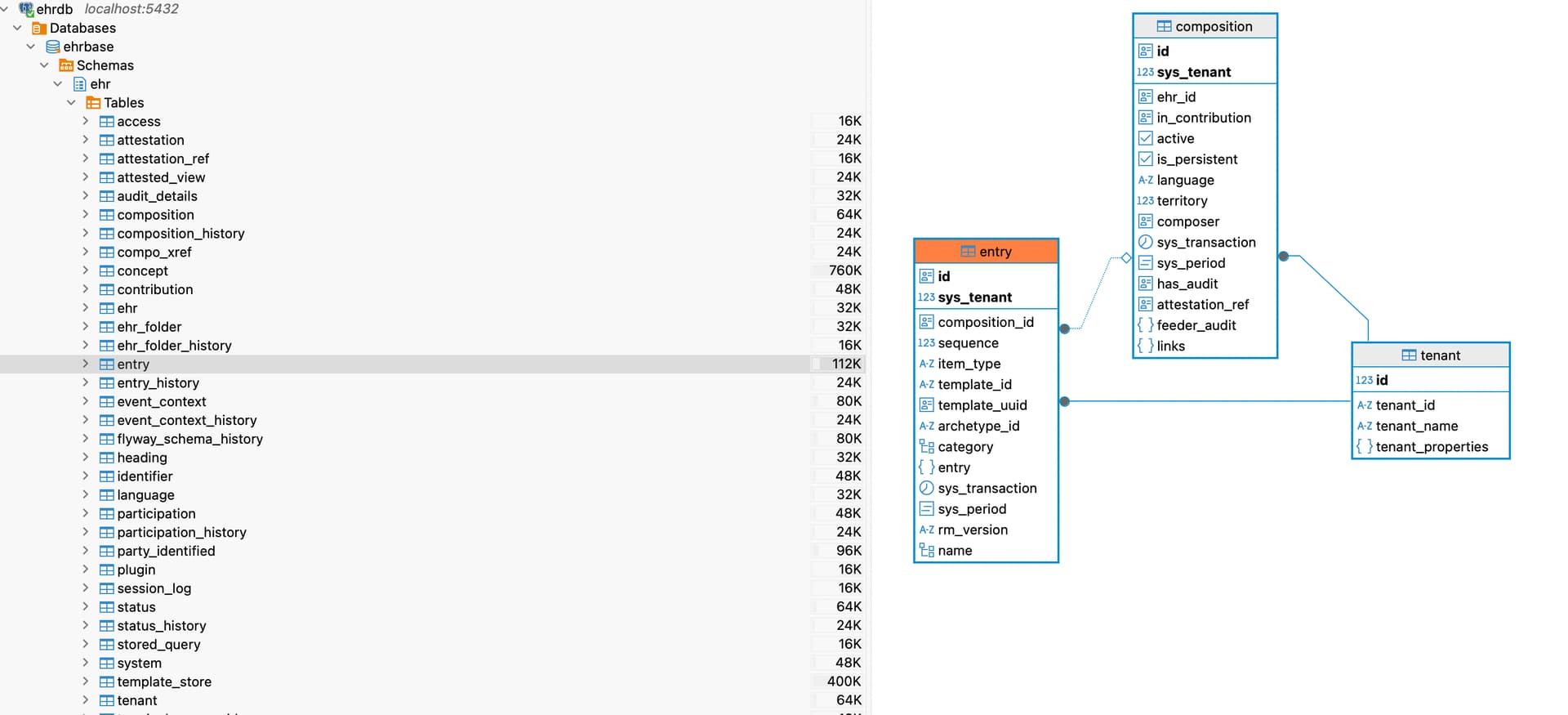
Since every change in a COMPOSTION in openEHR is a new VERSION<COMPOSITION> in a VERSIONED_OBJECT<COMPOSITION>, I struggle to understand how the database schema reflects that.
It looks like the VERSION attributes are (partly) in the ‘composition’ table, with the ORIGINAL_VERSION.data in the ‘entry’ table. (and this entry table has an ‘item_type’ column with example value: ‘care_entry’, and an ‘archetype_id’ column with example value ‘openEHR-EHR-COMPOSITION.vital_signs_monitoring.v1’, a care_entry is inside a composition.content.)
p.s.
I just read the change control specification after @thomas.beale posted: “openEHR already has a lifecycle that allows partially completed content to exist and to be committed to the versioning system, i.e. there is no problem committing a half-done questionnaire so that it is visible to carers; it can be marked incomplete.” (Scores or scales with mixed data types or explicit NULL values - #62 by thomas.beale)
I have to properly implement the VERSIONED_OBJECT and versions in my schema.
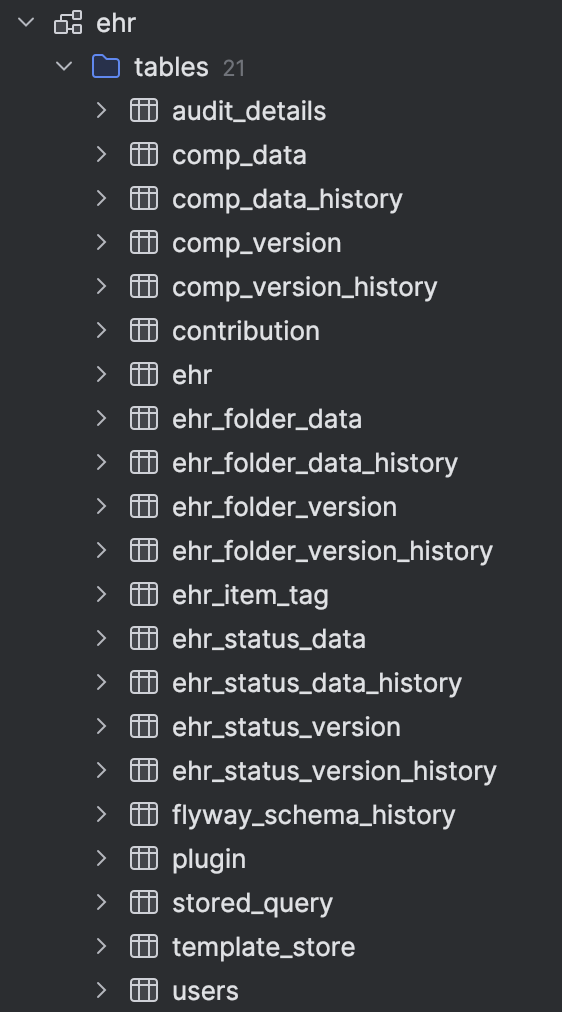
Thanks, apparently my ehrbase image was >1 year old. (I now added a bit more agressive pull_policy
Now my database schema looks much nicer and more like the expected VERSION (though it’s much harder to understand the data part now, it’s split up in many different nodes apparently. Probably as part of the new AQL implementation.)
re @thomas.beale’s comment:
There’s a lifecycle_state attribute on the IMPORTED_VERSION. Which, if incomplete, allows lower cardinalities and existence of nodes in a composition. I can’t find this attribute in the db schema or ehrbase source code. And I’m struggling to understand whether it’s supported.
If I call the /rest/openehr/v1/ehr/{ehr_id}/versioned_composition/{versioned_object_uid}/version api, I do get a response response_1745677577651.json (43.8 KB)
that includes a lifecycle_state that’s set to complete. (I am missing a * "_type": "ORIGINAL_VERSION", at the first line I expected from the openEHR REST API spec.)
But I haven’t found a way to check whether I can commit a VERSION with a lifecycle_state of incomplete.
Your “old” version of the data model piqued my interest since I’m working on a “pure” SQL implementation of openEHR (pure meaning 100% relational schema without using JSONB for storing hierarchical data). I know that @erik.sundvall advised us not to write another openEHR CDR, but I had too much time
Your “old” version has many tables with RM names and I thought that EHRbase is going 100% relational too. With your explanation it is obvious that they went away from it (which is obvious based on the highly hierarchical RM data).
I just want to see if standard SQL tools and language frameworks can be used for openEHR. Analysts would be super happy if they could just query openEHR data with the tools they already know (and skip any extra tools and APIs).
The main goal is to use existing frameworks for UI (v0.0.1 is already working using Jmix.io). I’ll publish an open source version if I succeed.
I added my own version of the lifecycle_state attribute just a day before Thomas mentioned it. This is an important detail for saving draft data during data entry as described in the specification. If I remember correctly, EHRbase (and many other CDRs) aren’t concerned with lifecycle_state since they leave that to the UI apps.
There is an old discussion on this forum if a second CDR instance could be used without validations:
Thank you @pablo for your suggestion. I’ve spent a few hours reading EHRServer code (my first Groovy codebase ).
My understanding of your approach:
DATA_VALUEs are stored as key/value pairs (key is the absolute ADL path) in DataValueIndex table (using DataIndexerService)
Versions for CONTRIBUTIONs are saved as XML to a file system (using XmlService)
Did I understand it correctly?
Since EHRbase is using PostgreSQL, JSONB serves the role of the DataValueIndex and XmlService (Postgres does the indexing and querying of hierarchical RM data stored as JSON).
p.s.
I don’t want to highjack this thread. It would be great to have another one for “EHRServer datamodel”. I can probably generate a diagram from your Docker.
Where do I find how the db schema relates to the rest api models? E.g. a post compostion creates a version of a composition record in the comp_version table and a contribution record in the contributions table. How do I find that code? (My understanding of Java is very basic) @vidi42 or @birger.haarbrandt (a)
Follow the controllers EhrBase is a Spring Boot application, at least the REST implementation is. Find the REST controller related to whatever you’re trying to learn (COMPOSITION etc), then follow the calls. POST would give you a good start. You’ll end up with the whole happy path all the way to postgres.
Focus on the big picture, main road etc. Don’t get stuck on the tricks it does on the way, they’ll be just functions call diverting from the primary execution path, but they’ll join that path when the call returns.
At some point you’ll hit some JOOQ calls pushing the DB representation of data to postgres.
Follow the same for the GET method from the controller for reads.
It’s not really key-value because at the same path you can have multiple indexes (for instance inside CLUSTER.items).
We do store a picture of the hole VERSION in a file for logging, that’s for creating and for updating COMPOS, and all are linked in the DB. IIRC the format of the file depends on the format of the original COMPO, so if it was JSON, it will store a JSON VERSION.
Now the schema in Atomik which is the EHRServer evolution is a little more complex, still not using any JSON stuff, but can, for instance, store demographic data.
PS: I don’t want to hijack the thread either, it was just that you mentioned building a SQL-only storage and wanted to point out I already did that so it might help for inspiration Also note what is difficult to do without JSON in the DB is the CONTAINS part of AQL, though in Atomik we have a table with parent-child node references to keep track of the tree but still don’t support AQL, we have a different querying mechanism like in EHRServer.
Ah, also, download Intellij Idea and use that. I think it’s free for non commercial use now. It may even give you the call graph I think from any function. f11 should be the bookmarks feature, so keep bookmarking as you read the code, then you can trace the calls from display bookmarks. (ctrl + shift + a → this gives you the ‘run any command’ dialog, in case you get exhausted looking for ‘display bookmarks’ etc )