I am new to OpenEHR & EHRbase concepts. I went thru the documentation of EHRbase and setup the app & db using docker images. I know there are APIs to manage the archetypes/compositions/templates, but is there is any EHRbase UI screens that will help to define/view it?
No - EhrBase (as for all openEHR CDRs) isa back-end datastore service. You can have a look at Medblocks for some ideas on how to help build UI but many openEHR applications will use standard UI frameworks and talk to the datastore via the API or proxy classes.
we build some commercial tooling around EHRbase which includes visualization and uploading of templates. Let’s have a chat if this is of interest to you.
Thank you Ian & Birger for quick response. I was exploring it to see if we could migrate EMR data into EHR base and then build an app on top of it.
To start with I wanted to see if I could setup a quick configurations of the archetype/compositions/templates, etc & setup couple of records for a Patient Problemlist diagnosis records and reverse engineer to see if we could do traditional ETLs to bulk load data into postgres database. Any pointers on bulk load will help.
very unlikely. Most standards based persistence implementations use all sorts of tricks at the persistence level to support acceptable levels of performance for OLTP. You’ll almost always find some sort of blob usage, which means traditional ETL (I’m assuming you’re talking about relational design here) won’t help you bulk insert.
Re bulk loading: openEHR currently does not define bulk insert operations within the specs, so any such tooling or feature implementation is bound to be CDR specific. @birger.haarbrandt would be the person to tell if they’re offering something for EhrBase.
A path available to you is to map your existing EMR data to openEHR, then make repeated calls to REST APIs to rebuild the same structure in an openEHR context, in EhrBase in your case. Not the easiest thing, but it would be same for any standards based platform implementation.
As @Seref has said, trying to ETL directly into the underlying data tables is definitely the wrong approach.
Importing via the REST API from an external source works really nicely - that’s exactly how we imported 50,00 live records from a legacy system into the One London UCP CDR, in that case from XML documents but the same could apply to a csv.
Any composition format will work but we found the FLAT format to be really easy to document mappings.
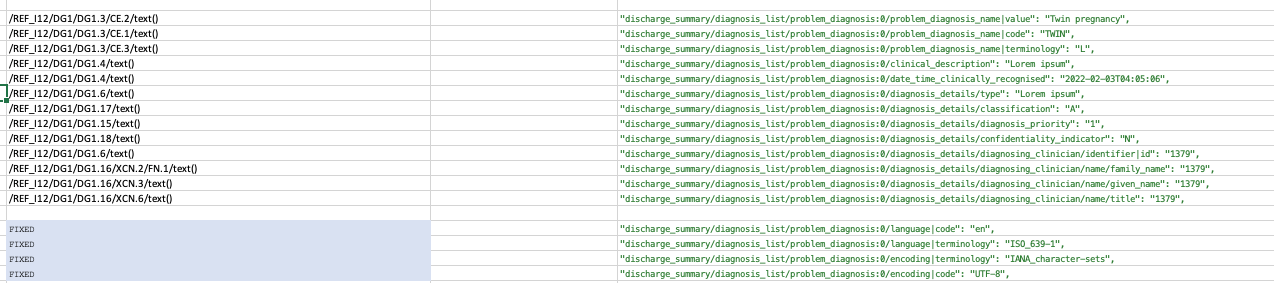
Here is a Snippet of our mapping document, that covers the problem archetype with in a discharge summary template.
THe xml document xpaths are on the left, and the openEHR FLAT paths on the right.
I forgot to mention, this would also bypass data validation performed during insertions via REST or other programmatic endpoints, so even if it was technically possible (many things are) to insert to DB directly, unless it was validated openEHR data to begin with, it would not be of use to anyone.
and the other main thing for new folks to understand is that the internal dbSchemas in openEHR CDRs generally bear absolutely no relation to the clinical objects you are importing i.e you will not find a ‘Problem diagnosis’ table anywhere in Ehrbase.
I forgot to add to that, that the trick here is to use the ehrscape template/example aPI call (supported by Better and EhrBase) to generate the FLAT format ‘target’ . It does need a bit of pruning to remove un-needed rm attributes, but works well.
That’s the fun bit you can choose whatever UX framework you want. We’ve built a platform that integrates with CDS apps too. Let me know if you want a show and tell of a vendor neutral platform.
Here is an example of mapping HL7v2 lab report status codes to the openEHR equivalent. You can use Snapper to construct them but easy enough to hand edit.
Nice, didnt knew these Concept Mappings existed. @ian.mcnicoll is there some specific tooling available for a v2 to openEHR transformation or did you use the usual suspects ?
Thanks everyone for your valuable insights. It is very helpful. I will stick to API calls to load data instead of ETL. Though I have worked on EMR data, this is the first time I am going to work with openEHR & EHRbase. I will do a quick proof of concept next week to understand the structures better.
Take a look at the integration tests repository from EhrBase team. The ones based on .http files would probably be the most helpful ones to get your head around how things work. The comments in the tests will tell you which Vs Code plugin to use to run them. CI pipeline tests are helpful too but they have too much python/robot overhead for a newcomer if you’re not experienced in those.
Hi, if your data can be converted into xml or json, as @erik.sundvall said you can take a look to FLATEHR. It is a low-code tool for creating compositions from different kind of sources.
You can use openEHR-tool to quickly view and manage data ingested on a openEHR instance.