The children of the openEHR-EHR-CLUSTER.exam.v1 archetype do not compile in ADL Workbench, and I would think in no other tool that tries to generate ADL2 form of these archetypes.
This is because the following element has been added to some/all of the children (which in ADL1.4 are in pre-flattened, not differential form), but has not been added to the parent.
ELEMENT[at0002] occurrences matches {0..1} matches { -- No abnormality detected
value matches {
DV_BOOLEAN matches {
value matches {true}
}
}
}
A secondary thing I note is that the generated ADL2 form of the child archetypes is (as far as I can tell) a pre-flattened form rather than a differential archetype - in the ADL workbench, converting ADL1.4 specialised archetypes to ADL2 involves diffing the two and generating the ADL2 from that. I don’t think that is happening here, but might be missing something. Maybe @pieterbos and @sebastian.garde have thoughts about this?
In the validation reports for the child archetypes such as https://ckm.openehr.org/ckm/archetypes/1013.1.3888/validation this discrepancy is reported as an error. We could of course make this type of error a fatal one and not allow the child archetype to be uploaded with such a problem at all.
It would not helped in this case though: The connection between child and parent revisions is always a problem though in source format. In this case, for the ADL2 conversion, the parent archetype at the time of upload of the child archetype would be considered. In this case this is Rev. 19 https://ckm.openehr.org/ckm/archetypes/1013.1.218/19/adl - and this archetype still has your at0002 ELEMENT.
This is a breaking change of course, and also one reason (I assume) why the exam.v1 archetype is now superseeded by v2. So I assume that the exam children will be updated in due course to be based on v2.
Could you explain where you notice this? Archie generates differential ADL 2 archetypes by default. The CKM certainly does generate differential archetypes in the examples which I checked. Archie uses a longest common subsequence diff based algorithm, which allows for much more sophisticated sibling order marker generation than the ADL workbench does. The code is called at archie/tools/src/main/java/com/nedap/archie/adl14/ADL14Converter.java at master · openEHR/archie · GitHub . The option to disable this is for use as an intermediate step in OPT 2 generation only.
Also the ADL 1.4 to ADL 2 converter is built to generate output even on incorrect ADL 1.4 archetypes. However, the output will be invalid ADL 2 archetypes, and if the validator is run against those, it will present validation errors. Subsequently either the ADL 1.4 source or the converted ADL 2 can be edited to repair any problems. As Sebastian noted as well by linking to the validation reports in the CKM.
THat would be trackable with ADL2 3-part version ids, but not properly in ADL1.4 - it would rely on CKM knowing what version of the parent to look at based on upload timestamp of the child.
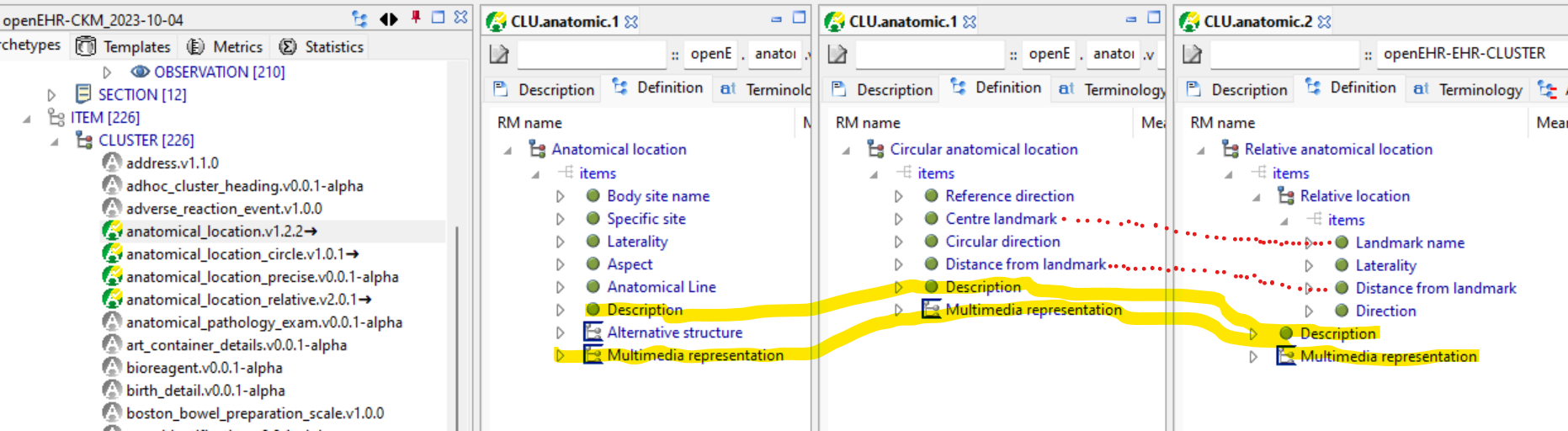
This is just one example of where child archetypes have forked from the parent and are no longer in sync. As pointed out in the past, the reaction of the modelling community is to mainly avoid specialisation at all, but that just creates new problems, where archetypes that obviously do have a semantic specialisation relationship are not formally related - e.g. the anatomical_location ones. The lack of specialisation means software can’t take advantage of re-use relationships or apply common coding rules to what are in fact the same data elements.
I don’t doubt this, but the ADL WB diff algorithm fails when the child archetype is not a valid diff w.r.t. to the parent, which provides a validity check. I’d have to spend some time to see what the current state of CKM specialised archetypes is using that check. I guess the Archie one should find the same validity errors?
Yes, that is what we are doing: using the parent that was available at the time of upload of the child (or if the child is uploaded first, the initial parent version).
We could add a 3-part version id for the parent in the other_details section as well for adl1.4 (like we do for the revision number itself). But, really, maintaining this - whether 1.4 or 2.0 - is the challenge.
These are really not good examples of where specialisation should be applied, IMO Neither circular or relative anatomical location is really a child of anatomical location in any meaningful sense. Yes they share some elements like description and multimedia but these are not likely to be cross-queryable. Similarly the relationship between landmark name/offset between circular and relative locations is tenuous - their use is very specific, with no practical relationship.
They are not in sync because there is no value (IMO) to keeping them in sync, only overhead
Yes, it should, and the validator does find them. Just the validity check is in the validator, not integrated in the converter. Both approaches should be correct, they just have different implications.
I wouldn’t agree there - they are all kinds of ‘anatomical location’ (at least as documented) - and one would normally expect to be able to define a slot that allowed a generic ‘anatomical location’ and any specific type to be used at runtime (as well as a slot that just allowed say ‘circular anatomical location’).
In an anatomy ontology, these specific kinds of anatomical location would be taxonomic children of a generic ‘anatomical location’…
Sure, but the the defining need for specialisation isn’t querying, it’s definitional re-use of common data points. So those two common data points ‘description’ and ‘multimedia representation’ are currently replicated in 3 archetypes - no-one knows whether these 2 fields across those 3 archetypes are intended to be the same thing or not.
If archetype editors decided to change either of those in any way, we would currently be in the position of having to find all the specific ‘xyz anatomical location’ and change all of those archetypes in the same way (or not?).
If these archetypes were specialisation children of a more generic parent containing those two elements, then you only have to change the parent, and the descendants pick up the changes.
If we were to model for an ontology we’d just be replicating SNOMED, a textbook or similar. We are actually modelling actual, messy clinical practice. Ontologies inform our modelling but don’t define it.
There are hundreds of archetypes (ie almost all) containing the same generic ‘Description’ data field and ‘Media representation’ SLOT, followed by a ‘Comment’ field. To create a specialisation based on this pattern is to create modelling and governance chaos with no semantic upside. Editors view the ‘Description’ and ‘Comment’ only as a generic, supportive design pattern that adds some value, especially in integration, but is not semantically critical to any archetype.
In the specific case of the anatomical location archetypes, after considerable discussion, the Editors/CKAs decided NOT to specialise because it obfuscated the clinical semantics rather than making them clearer. Yes, specialisation was considered and rejected. We could not identify an appropriate pattern to support specialisation, nor could we justify the existence of a generic parent in CKM that would be unusable and unimplementable and only cause confusion to modellers.
CKAs/Editors do specialise where it makes semantic sense and adds clinical value. We deliberately avoid specialising for academic specialisation’s sake, especially if it results in a generic, unusable and unimplementable parent. The decision-making is careful, complex and more nuanced than may be apparent at first glance to the engineers/implementers. We often do it very reluctantly due to the lack of ADL1.4 tooling support for downstream maintenance issues but we do it because we can clearly identify benefit.
Improving cross-collaboration between Specs committee and CKAs/Editors would avoid this kind of miscommunication and ensure that each group is not working in splendid isolation.
Indeed we are. Archetypes and similar artefacts are epistemic entities, standing in an is-about’ relation to the real world phenomena they document. Epistemic entities have (or should have) their own ontologies - essentially this just means that there are meaningful taxonomies in which they are arranged. Any specialisation relationship of archetypes, plus any relationship of a top-level archetype to its primary RM class (OBSERVATION etc) are such taxonomic relationships.
For the overall library of epistemic entities to function correctly, these taxonomic relationships need to be formally represented, and to allow substitutability of more specialised types in place of less specialised types, where the latter are defined. For example, a query engine being asked for all OBSERVATIONs (not clinically very useful) should pick up all ENTRYs based on OBSERVATION archetypes. Similarly, a query looking for CLUSTER.anatomical_location should pick up data created using any anatomical location specialisation.
When data are created, the same substitutability principle applies - a design-time specified slot or external reference for xxx could be filled by any specialisation of xxx.
(You can look up Liskov substitution for long descriptions of the principle in general IT)
So what this tells me is that the editors think that these archetypes named as kinds of anatomical location are not kinds of anatomical location but completely independent informational entities, and that further, there would be no circumstance in which a data property could be designated ‘anatomical location’, and different specific kinds of anatomical location could be used at runtime.
It also means that the description and media representation fields in those archetypes have no relation to each other.
There is no such thing as ‘academic specialisation’, only computational specialisation.
Specialisation is a key formal relationship between computational entities that has implications for :
modelling - are these common elements? => Re-use
runtime substitution (polymorphism)
querying: more specific forms of a general taxonomic kind will be retrieved when querying for the general kind
If these things are not observed in modelling, we wind up with formally incorrect systems.
I agree. One of the key improvements I have advocated for a long time now is for a technical review of archetype structures and relationships, to determine if their computational characteristics are optimal and/or correct.
This isn’t a criticism of CKM modelling work, it’s just to point out that in some cases, the model relationships won’t have the correct computational characteristics and sometimes won’t result in correct design time, query or application behaviour.
Specialization can have benefits, for querying but also for easier application development. But if we are to find any improvement there, we will need to collaborate and understand each others point of view. And for some of the often used patterns mentioned in this thread I think it could be worth exploring how to easier recognize these as the same things in software.
I don’t understand your concerns about these archetypes? - There is certainly a common pattern, but I can’t see any practical computational gap. IMO, we are never going to be cross-querying these items at a more abstract level. Basing them on an abstract parent would just add complexity without gain.
The best place to have these discussions is within the CKM reviews, as that is where these discussions about design patterns and use of specialisation actually take place. There certainly would be some additional benefit from discussing these issues at a higher-level.
I’m sure there are examples in COM of where different approach might have been helpful, but neither the screening or anatomical location archetypes , are from my POV, good examples.
Firstly, you never know what will be queried. With the current structure of the screening archetypes, there is no easy way to write a query that will obtain all the ‘screening purposes’ for all screenings for a patient, which seems a reasonable thing to do.
But querying is just one of three dimensions. The first one is design-time modelling: if some specific data points are common to a number of archetypes, but there is no specialisation, and at some point modellers decide that one of those data points needs to be changed (in any way whatever), you are up for making that change to the 12 screening archetypes independently (and maybe missing one or two) rather than just one parent archetype. For non-breaking (major version) changes, the 12 specialised child archetypes don’t need to be touched - compilers will just figure everything out.
The second is that there is no way to create an external reference or slot that allows any ‘screening questionnaire’ to be inserted at runtime. The only way to do the slot is using a complicated regex that tries to catch all the screening questionnaires - there’s no formal substitutability.
Another issue is that code generators won’t be able to leverage any commonality, because it is not declared. This is as bad as FHIR, which is a disaster in this area - every resource (many with numerous common properties) is treated as its own thing. Code generators can generate any common code, or obtain any re-use.
In summary, it doesn’t really make any difference if we think that no-one would write a query on the common attributes (and I maintain, we can never know that); there is a question of re-use of common elements that matters in downstream data and software.
Well maybe… but it doesn’t make sense to me at least to be re-hashing general principles on a per-archetype basis - the principles are universal. The only question at a per-archetype level is whether the archetypes in question form a specialisation hierarchy or not.
This is a VERY IMPORTANT statement which everyone in this thread should follow.
The review of archetypes is the key part of openEHR. This is where clinical and technical views should be merged into improved knowledge and skills.
The inheritance vs composition topic has been ongoing for years. We need to work this out and I really think the review process is the right way to work on this.
I think any clinical concept have some specialisation hierarchy. The problem is that they almost always belongs to multiple hierarchies.
Exam is an example of this. The concept can be defined by the type of examination or the anatomical location examined. What is the best pattern? When to discuss that topic?
The review of the archetype is a good context for such discussions. IMHO