Hi! I am having some issue in the archetypes versions.
I am using a lot of CLUSTER.exam specializations such as
CLUSTER.exam-muscle,
CLUSTER.exam-heart,
CLUSTER.exam-neck,
etc etc
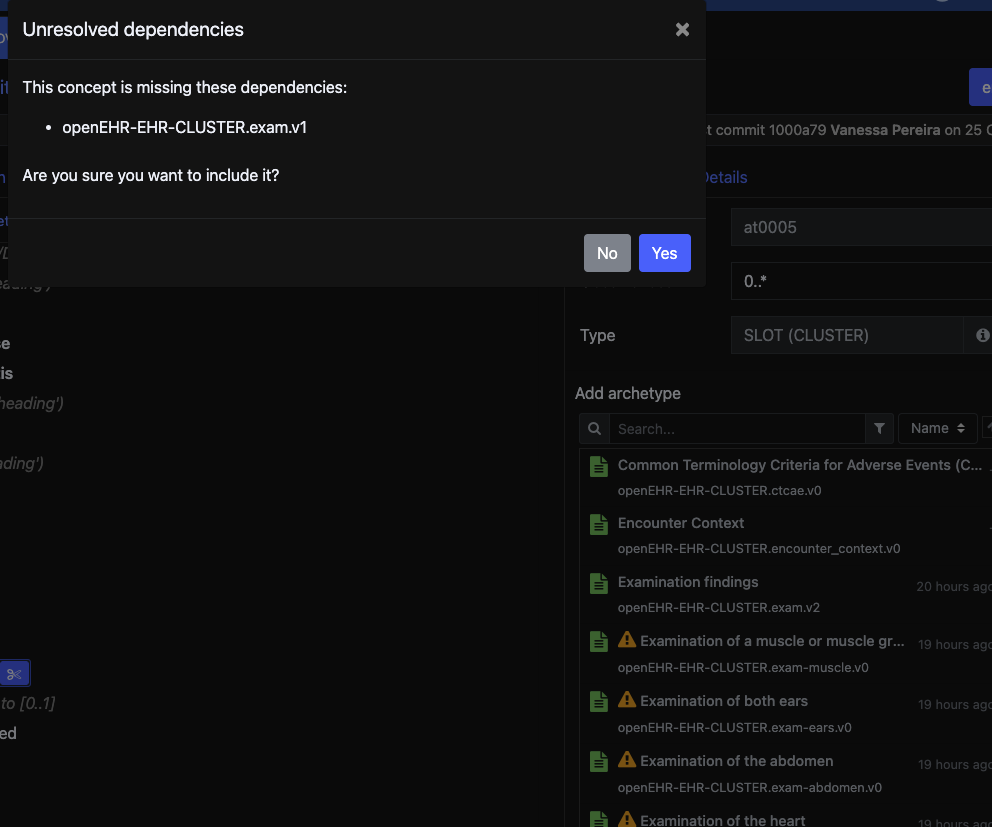
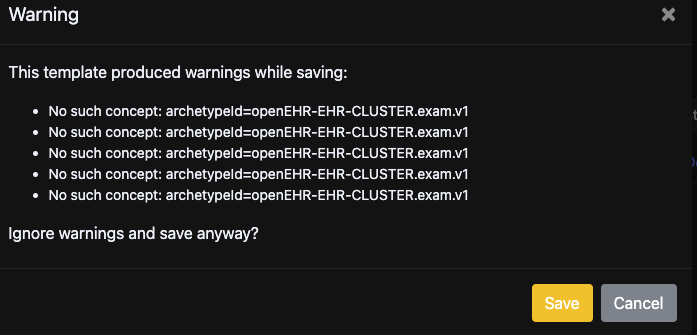
but all of these point to a parent archetype CLUSTER.exam.v1 and on the CKM there’s CLUSTER.exam.v2
In order to keep everything consistent, should I download CLUSTER.exam.v1 instead and keep using it? Whats the correct procedure to do in this case?
Are any updates to the specializations planned any soon so these archetypes can comply with each other?
Also, if i want to create other specializations from the CLUSTER.exam, should i do it from the CLUSTER.exam.v2? or CLUSTER.exam.v1 to keep the same structure from the other specializations? I will check both versions in detail to see what are the breaking changes, but just want to be sure about the correct procedure.
Hi Vanessa!
The v1 is per now in status Reassess, and if you look closer to it, it is identical to v2. Which is a kind of weird. The main difference from the latest version of v1 before it was updated according to Change Request 845, is that “No abnormality detected” (NAD) element has been removed. See change request 845 of details. Removing an element is a breaking change, hence the v2.
All specializations of the archetype were made before it was updated, so they have the NAD element. None of these specializations have been published, and should not be used. They should all be moved as a specialization of v2 to reflect the new design, and then put on review. As far as I know, the specializations haven’t been thoroughly investigated, so there might be a need for redesigning them. @heather.leslie might give more details.
Per now there are nobody in charge of tidying up the international CKM, so I have unfortunately no answers for how and when this will be fixed.
NB: this happens because in ADL1.4, a specialised archetype is just a copy of the parent with modifications. In ADL2, a specialised archetype is a differential artefact (like a descendant Java or Python class), and the result of the specialisation with respect to the parent is always computed - no changes would be needed to the child archetypes, other than the id of the parent. Possibly a motivation to move to ADL2
In a few weeks, I hope we have the new Clinical Program running, and that group will be able to decide what to do.
For this very reason we’ve been motivated for years to move to ADL2 for archetype modelling and governance. The problem is that it isn’t supported by the CKM.
thanks @varntzen
i was using them but i see that there are too many inconsistencies between element and their atcodes probably due to not being check up or used that much. I would still use some of them - its for a registry, i guess the worst thing can happen is a later remapping to new versions but i don’t see that happening in a short term, but will have that pointed out.
@siljelb , @thomas.beale there’s any ehr server that supports ADL2? and modelling tools? do you know any system based in ADL2 in production? I am curious about the procedure that needs to be taken
I have never worked with this version before but i see that on CKM it has an option for experimental ADL2.
What could happen to systems based on ADL1.4 if ADL2 will be used next? a complete refactor?
As far as I’ve understood, we should be able to model and govern archetypes in ADL2, but export to ADL1.4. I think only Nedap’s CDR uses ADL2 natively.
@ian.mcnicoll may have already explained this, and may be able to point to a post. A rough summary (he’ll correct me
Tools:
Better’s Archetype Designer is 95% ADL2 internally and even supports ADL2 templates (they look like this - keep scrolling and you’ll see the template overlays - they’re just little archetypes); it does ADL1.4 archetype conversion on the fly in and on save. @borut.fabjan may want to say something further on this.
LinkEHR supports about 80% of ADL2 internally - @yampeku can provide more details
Nedap’s Archie, and any tool that uses the archetype code from Archie (currently includes Nedap’s own modelling tool) is 100% ADL2. Archie supports ADL1.4 → ADL2 conversion on the fly reading in; can’t remember the status of writing out ADL1.4. @pieterbos can provide more info if needed.
CKM - CKM uses Archie ADL2 code to do (I think) validation. But a lot of other things would be affected if CKM was made ‘native ADL2’, so there’s no instant fix available. @sebastian.garde will have more up to date info.
CDRs - most CDR products are based on OPT1.4 templates. Since they don’t use ‘source form’ templates, they don’t really care about the differences between ADL1.4 (i.e. .oet) and ADL2 templates or archetypes. So the main challenge is moving to ADL2 in the modelling realm and being able to generate OPT1.4 OPTs for some time, while the CDRs catch up.
the above characterises all CDRs except Nedap’s, to my knowledge.
These issues are now part of the scope of the Clinical Program (as well as on our minds in SEC and elsewhere of course), so I think if you work through some discussions among modellers, tool builders (including CKM), the steps to moving forward can be worked out.
Yes I think that number is right. In any case any new version of the tooling we develop (for example a web-based linkEHR) will use archie internally for sure. Currently we can import ADL2 archetypes but they are transformed to ADL1.4
I would love to move modelling to ADL2 first. In my experience it’s great, and solves the issue described here (and many others). Which will enable us to use the specialisation pattern much more often, which I think will be of great benefit in more scalable modelling. I especially like templates to be defined in ADL, because it allows for hand editing, and is human readable.
Our adl2 modelling tool is semi public and free at https://archetype-editor.Nedap.healthcare also check out the advanced view. Support is available only for our EHR suite customers and best effort otherwise via discourse.
Maybe we could make funding available to the clinical program to support ocean to develop the needed adl2 features. @sebastian.garde what are your thoughts around this?
One thing to review is the consistency of adl1 <-> conversion. Especially around at codes and nodeids. I think this is only an issue when converting from 1 → 2, because adl2 has more atcodes/nodeids. So if we move to ADL2 modelling first and do the conversion in CKM, we might have solved enough of this challenge. @pieterbos could you confirm this please?
Pieter has probably already got all the logic working, but just in case, here is the wiki page that has (AFAIK) the right algorithm for bidirectional code conversion.
@pieterbos / Archie’s conversion log works very well.
Pieter and I have validated (and finetuned) this by integrating it in CKM to - reliably - convert the various revisions of an adl14 archetype to adl2 while keeping the at/id codes consistent even with node deletions and additions.
So 1.4 → 2 conversion works quite well in CKM using Archie.
(There is the issue that you can only guess which revision of a specialisation belongs to which revision of the parent.)
Anyway, next step would probably be a 2->1.4 conversion.
If that works reliably as well (so that ideally you can round trip as far as that is possible), that would be an important step to also enabling adl2 archetype upload and basing more and more components directly on adl2, but continuing to offer adl14 export (and import as well of course ).
Funding obviously never hurts, if only to prioritize.
The main issue with adl2 support is that it is one of the greatest (complex + comprehensive) changes to a tool like ckm that I can imagine.
Do we have an explanation of specialisation semantics for 1.4 in specs? Current archetype technology overview document reads as a description of ADL 2.0 flavour of specialisation.
I had to look back through old releases - the AOM 1.4 doc has this para (oops):
Archetypes can be specialised. The formal rules of specialisation are described in the openEHR Archetype Semantics document (forthcoming), but in essence are easy to understand. Briefly, an archetype is considered a specialisation of another archetype if it mentions that archetype as its parent, and only makes changes to its definition such that its constraints are ‘narrower’ than those of the parent. Any data created via the use of the specialised archetype is thus conformant both to it and its parent. This notion of specialisation corresponds to the idea of ‘substitubility’, applied to data.
ADL 1.4 doesn’t discuss specialisation other than to mention the specialise section.
But here is what was in ADL 0.9 document (2004) (added bolding):
5.4 Specialisation
Archetypes can be specialised. The primary rule for specialisation is that data created according to
the more specialised archetype are guaranteed to conform to the parent archetype. Specialised arche-
types have an identifier based on the parent archetype id, but with a modified section, as described
earlier.
Since ADL archetypes are designed to be usable in a standalone fashion, they include all the text of
their definition. This applies to specialised archetypes as well, meaning that the contents of the ADL
file of a specialised archetype contains all the relevant parts from its parent, with additions or modifi-
cations according to the specialisation rules. In an analogy with object-oriented class definitions, ADL archetypes can be thought of as always being in “inheritance-flattened” form. Validation of a
specialised archetype requires that its parent be present, and relies on being able to locate equivalent
sections using node identifiers. For this reason, nodes in specialised archetypes carry either the same
identifiers as the corresponding nodes in the parent, or else a node identifier derived by “specialising”
the parent node id, using “dot” notation. The following describes in detail how archetypes are special-
ised.
I started work on ADL2 in about 2007, so it looks like I never attempted to write an explanation for 1.4 - and there is no good explanation available. ADL 1.4 archetypes are pre-flattened archetypes, so specialisation = copy+fork.
The only workable form of specialisation of anything is always differential
Thanks Tom. It did not occur to me to look at pre 1.4 versions of ADL docs. I suspect another form of useful information is the content in the wiki. The current link to wiki links in the AM landing page (at least for adl I think) is broken, but I did a search in wiki for adl and lots of useful stuff came up. I did not go through them.
The reason for the question and for me looking for documentation is to have a clearer picture of the changes to how specialisation is handled at the syntax/semantics level. There’s knowledge in the form of code in Archie etc but that’s not as convenient as having it in the specs I’ll try to spare an hour or so today to do some reading. I have not touched this part of things for years, good to refresh every now and then.
The AOM2 spec has specialisation semantics all over the place, and you will see a lot of conformance functions like this, where the ‘other’ parameter is the corresponding node from the same archetype.
--
-- C_ATTRIBUTE conformance to parent
--
c_conforms_to (other: like Current): Boolean
-- True if this node on its own (ignoring any subparts) expresses the same or narrower constraints as `other'.
-- Returns False if any of the following is incompatible:
-- * cardinality
-- * existence
require
other /= Void
do
Result := existence_conforms_to (other) and
((is_single and other.is_single) or else
(is_multiple and cardinality_conforms_to (other)))
end
c_congruent_to (other: like Current): Boolean
-- True if this node on its own (ignoring any subparts) expresses no additional constraints than `other'.
require
other /= Void
do
Result := existence = Void and ((is_single and other.is_single) or
(is_multiple and other.is_multiple and cardinality = Void))
end
existence_conforms_to (other: like Current): Boolean
-- True if the existence of this node conforms to other.existence
require
other_exists: other /= Void
do
if existence /= Void and other.existence /= Void then
Result := other.existence.contains (existence)
else
Result := True
end
end
There’s also section 8.1.2.2 on validation, flattening and diffing.
The documentation isn’t as good as I’d like - even with pulling a fair bit of the code from the ADL2 workbench where it was worked out. There’s a lot of code in there that is reasonably readable if you want diffing / flattening algorithms for example. The 3 phase validator also is useful to understand details. Getting these algorithms right (according to the regression tests took about 5 years.
Archie’s equivalent code is mostly under tools, and I seem to remember @pieter telling me he created different (maybe more concise) diffing and flattening algorithms.
And I look forward to se a more formal description on how specialization should be used, when to use, pros and cons for the clinical modelling.
Over years I have moved more in the direction of slots with specific clusters for specific details. IMHO this is a more scalable approach than speciallsation. I think this is not (only) a AM/ADL question. I am afraid people will use to much speciallsation if it gets møre easily available.
The problem described initially in this thread will be there also with ADL2!? When creating hieraechical bindings there will be an issue with changes. This will degrade the overall capacity of change in openEHR modelling.
I have not yet seen descriptions on how this will Impact the overall governance of archetypes .
The answer from @siljelb is good. Still the question on management is not (only) about the problems with ADL1.4 and copying. No matter how this is technically implemented or managed you still have the semantic and governed connection which needs to be managed in the long run. We can make it technically simpler, but the information model is at the same complexity which only a few globally will be able to cope with.
Well we actually need both. Consider any archetype with a slot for some purpose like ‘device’, or ‘physical exam’. What do you want to allow in that slot? Archetypes for devices, or for physical exams. Now, if you can specify the slot with a constraint like openEHR-EHR-CLUSTER.device_description or openEHR-EHR-OBSERVATION.physical_exam, and there are specialised children of both those, then there is nothing else needed. But if there is no specialisation, a) those archetypes can’t be authored properly in the first place, and b) specifying slots becomes a real problem - you are stuck with enumerating all the possible device archetypes, physical exam archetypes. And that list keeps changing. You can fake it a bit by requiring that all the names of those archetypes match some pattern, and that will work, but it provides no guarantee of what data points could appear in the slot, whereas with specialisation, you are guaranteed to have certain data points.
So it’s really about how we achieve re-use and the balance between composition and specialisation. If we throw out specialisation altogether, we lose first class substitutability, which really reduces the power of any formalism.
We rarely specify which archetypes should go into a SLOT, most commonly keep it open for any archetype and leave it to the template. Or, in cases where we know one or several archetypes, we add them as “included”, but still don’t restrict others. Only in cases there is no doubt, or there is no thinkable use case for other archetypes we restrict to named archetypes.
Our advice to new modellers is very much in line with what @varntzen and @bna towards less inheritance and more slot-filling/aggregation. ADL2 will actually help that since it essentially allows those slot-fills to be fully concretised. Pretty close to Embedded templates but where e.g. a Cardiac ultrasound imaging result is specialisation of the generic imaging result but where the new content is defined by a slotted in details Cluster archetype. In my head I’m calling these ‘aggregated archetypes’.
And I totally agree with keeping slots open in those generic archetypes.