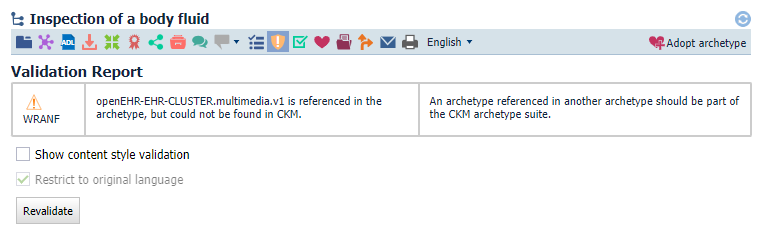
I notice there are numerous archetypes with slot definitions containing a match for a CLUSTER.multimedia archetype that does not exist in the CKM, but presumably did at one time.
When an archetype deletion is made, I would think that a check should be run that would detect slot match expressions that no longer match anything at all. This does not appear to be occurring, with the result that there are archetypes containing slots that, over time will never match anything. This may become a serious problem…
The bad news is that I have broken this bit of functionality.
Completely my fault (and, well, a little bit Apache’s for treating split characters as a literal, unlike Java that uses the same name but interprets it as a regex…thus the split result is VERY different for the pipe char…). Anyway, we will fix this.
As for checking this before deleting an archetype…true, but we’d need to run the validation on all archetypes except the one to be deleted for this purpose which is a bit of a performance problem. Agree this would also be helpful to a degree but I don’t think that editors delete (or rename) archetypes light-heartedly…which can only be done for unpublished archetypes anyway.
Good to know, but still, there are quite a few broken slot regexes, some pointing to archetypes that don’t exist, others to wrong versions (= archetype that doesn’t exist…). Examples:
many archetypes → CLUSTER.multimedia.v1
various, including OBS.blood_ressure → CLUSTER.level_of_exertion.v1 (but v0 exists)
This is just from a manual check - there will be more.
Two problems seem to be occurring:
slots point to wrong version of an archetype that does exist, but not in that version. THis is probably mostly when a slot reference is not upgraded to a higher version when the target archetype is republished in a higher version. This would be a check that should be run when some other archetype is to be republished in a new major version.
in at least some cases, removing even the major version from the slot reference would be reasonable, e.g. it just resolves to the latest version of the target, including major versions.
slots point to something that just doesn’t exist, possibly having been removed earlier.
as mentioned above, a check should be run when a deletion is proposed. If a deletion is really a rename, e.g. it seems that CLUSTER.multimedia has become CLUSTER.media_file, then all the relevant slot refs need to be fixed as well.
This would be the default modelling pattern if it was supported. Last time I checked, CKM didn’t support slot include regexes without the major version. In practice we often add both the v0 and the v1 for archetypes which haven’t been published yet, to avoid having to go back to fix the regex once the archetype is published.
That’s correct, multimedia became media file. Ideally this kind of check could automatically fix any affected regexes whenever an archetype is renamed.
Awesome! The problem is that in order to do this we need to manually edit the ADL. Archetype Designer currently outputs a regex like this if one unchecks the “version” checkbox:
…and that regex from AD will NEVER give you any valid archetype id at all, because the regex cannot match any valid archetype id. I now remember that discussion…
@borut.fabjan In my point of view, the regex AD uses here is simply wrong: It can never match any valid archetype id.
There are several easy ways to change this, my preferred one is
include archetype_id/value matches {/openEHR-EHR-CLUSTER\.device(-[a-zA-Z0-9_]+)*\.v[0-9]+/}
The reason that this is my preference is mainly because it
clearly states that you expect all archetype versions to be included here, and at the time
is still reasonably simple.
But there are other options of course, simpler or more complex ones…
It would probably be better if the regex allowed 1-, 2- and 3- part version ids at the end, even though they will never turn up in ADL 1.4 slot filling statements. The reason is that if we do this, the slot refs don’t have to be reprocessed to allow them during conversion to ADL2 archetypes, where such refs can be used.
It’s also not really correct to have such restrictive regexes in slot references, since if we decided to change what chars were legal in archetype ids, all slot refs would become invalid. They should instead be permissive, e.g. something like:
That would be fine with me and I agree with the points you make.
However
(-[a-zA-Z0-9_]+)*
is the well established way of allowing specialisations in slots for years and you’ll find it in archetypes everywhere. In CKM, we pick up this pattern to determine that specialisations are allowed display “and specialisations” - we can of course finetune this, but it needs to be determined from the regex somehow and established patterns certainly help.
I am also happy with the more general version identifier:
…but the distinction between . and . is easy to miss and makes it harder to understand what the regex does. Maybe this part of the ADL is not meant to be human-readable after all
Anyway, my main point is that the current expression produced in AD when you want to allow all versions creates a regex that cannot match ANY legal archetype id at all. So we cannot “support” it in CKM and Silje and others cannot use it to create version independent slot assertions. Or am I mistaken here?
Off the top of my head, I can’t remember any use case where we’ve intentionally left out specialisations from SLOT includes. @heather.leslie, do you know of any?
Hmm - not so black and white here. There are situations where it doesn’t make sense logically in which case I tend to default to not adding the specialisation to be honest, mainly because it requires extra steps when I’m not convinced of the value. Then it becomes a consistency issue - you add them always, I may add them inconsistently, and others may not even think about it.
However, if adding specialisations is considered by Editors as the ideal way of modelling, then the opposite is more of a concern to me…
The extra step required to make a SLOT include any specialisations, much less all specialisations, for a specific archetype requires a deliberate modelling choice to go through extra steps in the majority of modelling situations. Amplify that for every archetype included in every SLOT and it contributes significantly to the burden of modelling, especially from a quality/consistency POV - it is totally dependent on each modeller to make it happen in every situation. And we forget, or we are in a hurry or…
It may be worth considering changing the way specialisations are added - making it a tooling default to add version-independent specialisations with every include to a SLOT. In that situation, the burden of modelling is changed to exclude all specialisations or limit the include statement only to one version of an archetype in the outlier situations where specialisation needs to be limited or removed.
One thing to know is that in ADL2 you don’t always need to use a slot to connect two archetypes. In many cases, a direct reference is simpler, where essentially what is going on is re-use of a single well-defined content sub-tree e.g. ‘device’ (including specialisations), rather than a true open slot.
For example, in the BP archetype, probably all the slots could be replaced by direct references (use_archetype statement). If this were done, specialisations of any of those archetypes can be used at runtime. This approach to connecting archetypes enables tooling to work on a semantic basis, rather than trying to match ids to regex constraints (the current slot approach), and it enables the tools to build full templates at design time, rather than waiting for runtime.
Slots in the future (ADL3) would probably become a statement more like an external reference that allows a logic expression, e.g. something like CLUSTER.specimen OR CLUSTER.specimen_container.
I’m not claiming that any particular node needs to be a slot or a direct reference, that’s a clinical modelling call, but using direct refs & specialisation in a lot of places will be very helpful in the future.