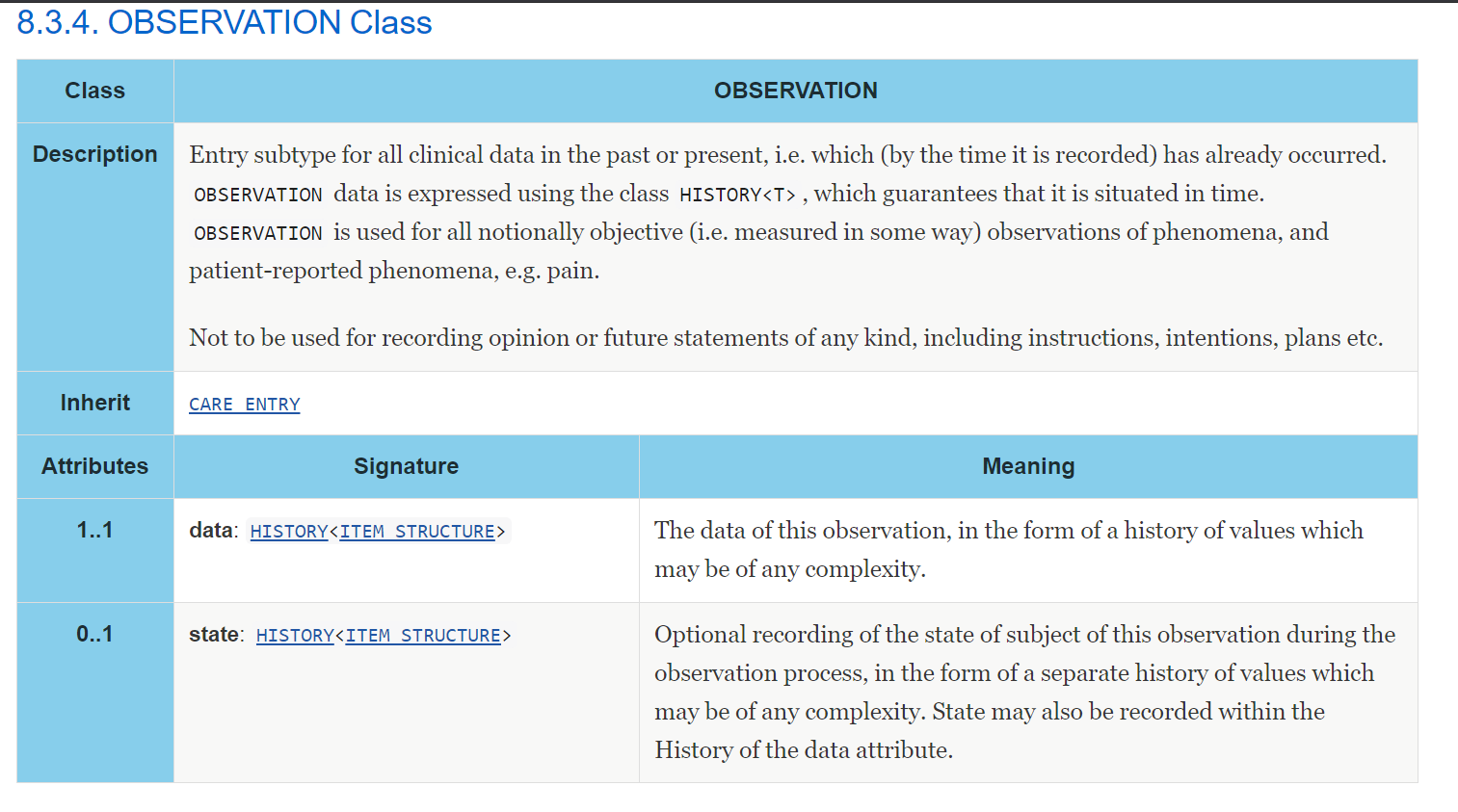
Examing the body temperature archetype for a use-case where I are to add CLUSTER data for both environmental conditions and excertion. These are defined as SLOT in the STATE attribute of the OBSERVATION. So far so good.
State is defined as part of the state attribute of the OBSERVATION:
The RM defines that data and state are separate attributes. But when I look at the modelling tools like Oceans Template Designer or tools.openehr.org I find that they both add state as part of data and below the event. Which means that state will be repeated for each event.
This is not the intention for my use-case. I want to define the state for all events in the observation. I.e. I will record the temperature for over a period of N hours, minutes. And the state remain the same.
Did I misunderstand something? Any thoughts on this?
If I’m not mistaken, I think state is intended to be part of the events. In use cases like for example stress testing where you’re measuring a set of vital signs while the subject is running on a treadmill, the state will potentially be different for each measurement. If your state data is predictably constant throughout a series of measurements, isn’t it really a protocol for the test?
use the per-Event state attribute if the state is recorded with the Event.data, i.e. you sample both the focal datum and body state at the same time, i.e. each ‘state’ is the state at the time the datum had value xxx
use the Observation.state if the state data is indepdendently sampled and collected, i.e. probably the treadmill example, where the heart rate (ECG data, whatever…) is collected (say) every millisecond and the treadmill data (= proxy for exertion) is collected every second, and probably not even synchronised with the other data. Interpreting the ECG data requires interpolation on the treadmill/exertion graph.
So these choices are to enable typical ways of data collection to occur.
I have not checked what the tools do at the moment, but they should support both options, it’s part of the core RM.
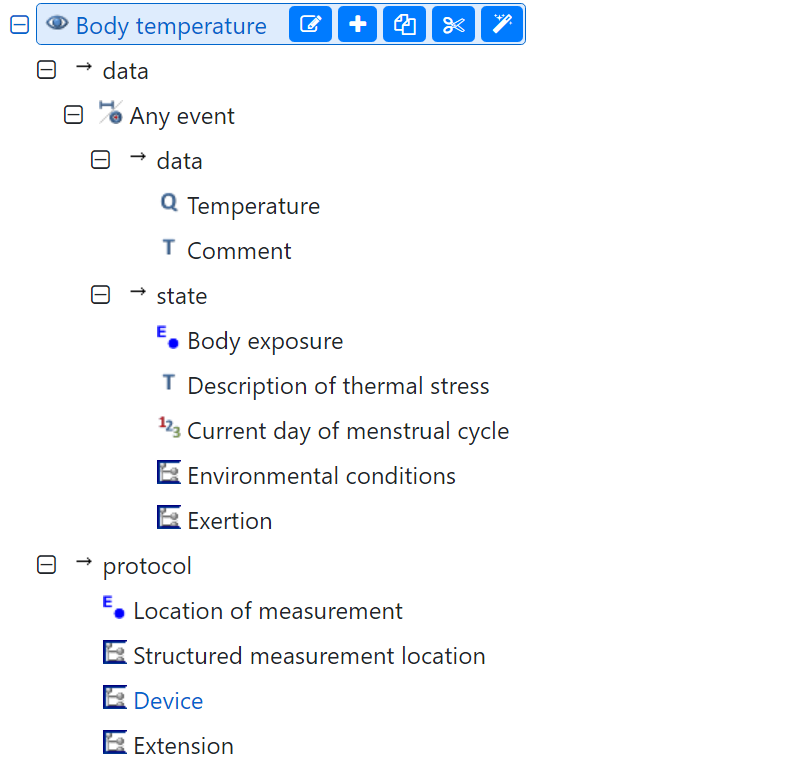
You are right, as always, Thomas. And it’s more like I remembered the specification as well. But looking into some archetypes it seems like state always is added to the event. Take Respiration as an example: https://ckm.openehr.org/ckm/archetypes/1013.1.4218
From the CKM it seems like the state is separated from the EVENT:
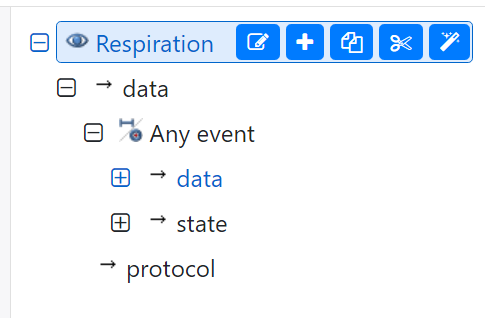
But looking at the actual archetype it is part of the EVENT. I.e. like this screenshot:
This means that the state information modelled into the respiration archetype is to recorded as part of every event registration. This is the intention by the clinical modellerer and me as an implementer must follow these guidelines.
Tbh I didn’t know about observation.state. It makes sense to be able to have either. But shouldn’t we then be able to model state once within the model, and then choose to use it either as part of or outside the event, in a template or at runtime?
Well that is actually a key question. When is such decision to be defined and constrained in the archetype and template, and when should it be a runtime decision for the end user?
I don’t have the answers. But I guess the most correct answer is: It depends.
If many or maybe even most modellers, like me, was not known with this feature in the tooling : Are there any consequences for the approved archetypes out there?
It will make a change for queries because the semantic of the state information is different.
Maybe, but probably only non-breaking changes. All the published international archetypes have been modelled on the basis of state existing within the event.
The per-Observation.state feature was supported in Archetype Editor but I don’t think it was ever used, and I’ve never used it myself. Whilst in theory, it does all make sense, in practice I suspect the usage for a 'global state 'is quite narrow. Just for consistency, I’d probably be happy to stick with per-event state and accept the ‘duplication’ of data across each event.
Well this could make sense as a smart feature in a tool. To make it work technically, it would require the tool to allow the user to define just the ITEM_TREE or CLUSTER of the data points required to capture state, and then it would have to secretly replicate this in OBSERVATION.state (wrapped in a HISTORY of EVENTs) as well as EVENT.state within OBSERVATION. Every time the modeller changed it, the tool would need to change both.
Then in a specialised archetype or template, one or other (or both) of those states (i.e. OBSERVATION.state and OBSERVATION.data.items.state) would be removed as unneeded.
Not every user might want this - i.e. some super-techie users might have reasons for explicitly constraining OBSERVATION.state as a distinct HISTORY/EVENTs structure, as is possible now. For example, they might really want to say that the OBSERVATION state consists of 1 min samples, and has some of the other possible attributes that are defined on HISTORY and EVENT (in deed
So this feature wouldn’t be a completely straightforward one to implement in tools, but I can see the attraction of it. I suggest you ping the usual suspects (i.e. Sebastian G and the tooling experts) to see what they think.
I came across this issue working with some integration use-case. The solution, in short term, will be to duplicate the data. But when looking at some of the vital signs observation archetype I suspect some state attributes to more of a “per-observation” statement.
I am not the one to decide that being purely a technician these days. Just asking the questions