When we reference archetypes within other archetypes, it has been customary to include the major version number of that archetype. This is generally unnecessary since a new major version of the same concept has the same (but possibly additional) use cases as the previous major version. It also makes governance harder, since it means every time an archetype is republished as a new major version, even from v0 to v1, all referencing archetypes need to be changed too.
Archetype Designer now includes the option of leaving out the version number:
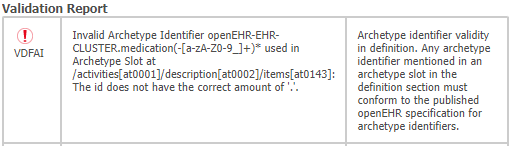
Unfortunately, the CKM doesn’t accept this, instead requiring that “any archetype identifier mentioned in an archetype slot in the definition section must conform to the published openEHR specification for archetype identifiers”:
What is the current status of the published openEHR specification for archetype identifiers? Is Archetype Designer allowing the modeller to do something illegal, or is the CKM just not up to date with the latest news?
To me this looks like the regex pattern created here does not allow a second “.” - i.e. the “.” before a v1 or v0.
As a consequence, no valid archetype could EVER be constructed from that regex and thus no archetype (with a valid archetype id) could ever be included in that Slot. So, I think that it is fair for CKM to warn about this.
I’m happy with that, but does that mean that tools should make this regex for example ^openEHR-EHR-CLUSTER\.medication(-[a-zA-Z0-9_]+)*\.v([0-9]|[1-9][0-9]+)$ when version is excluded?
(Edit: Currently the CKM doesn’t accept this. I suspect it doesn’t understand the pipe.)
As far as I understand VDFAI, it only requires the regex provided to possibly match a correct archetype id.
The regex - when provided at all - is not required to exclude all strings that are not archetype ids.
The pattern you suggest above should work minus the ^ and $ markers indicating start and end.
In my understanding ^and $ are just assumed at least for adl 1.4 archetypes - the pattern always refers to the whole.
should also not trigger a VDFAI validation error because this regex can match many valid archetype ids.
(Unfortunately, there are unlimited ways of specifying numbers at the end in a regex, therefore in CKM we check for a few common patterns and if they fail, we test if the pattern can match at least one specific version number at the end.)
Conceptually that is probably true, but if you allow artefact A.vN to reference artefact B.vM, and then you want to change the ref to B.vM+1, which is technically a different model, then you need to up the version of A.vN to A.vN+1 as well, since now effectively you have a different model of A. This is (unfortunately) standard version logic, and any good versioning system follows it.
Consider an application using some Evaluation.cancer_diagnosis.v1 archetype, which currently references Cluster.tnm_staging.v2; now you replace the latter with Cluster.tnm_staging.v3, which contains (let’s say) rewritten NCI TNM staging representation, which is essentially based on new theories/science of TNM staging. If you upgrade Evaluation.cancer_diagnosis.v1 just to (say) Evaluation.cancer_diagnosis.v1.1 which contains a ref to Cluster.tnm_staging.v3`, any user of that archetype (e.g. some application software) will now contain breaking changes in its OPT structure down in the TNM staging cluster, and won’t be able to deal with it.
What really should happen is that the Cluster.tnm_staging.v3 should only be included in a Evalation.cancer_diagnosis.v2. The effect of this is that there are now in existence:
old style TNM staging based cancer diagnosis Eval archetype
new style TNM staging based cancer diagnosis Eval archetype
These generally both need to exist, since although leading edge medicine might have moved to the new TNM staging approach, many institutions around the world cannot move that fast (and anyway, their own national cancer institutes may think they have better ideas than NCI), and need to keep using the old one.
Any time the major version of anything is incremented, it is the same as forking or replacing the old product with a new product. Only minor and patch level changes are considered to be part of the lineage of the an original artefact/product; a new major version is a new lineage.
I’m choosing to focus on this part of the response, since it reflects how we govern archetypes. If a TNM archetype contains explicit content from a specific TNM version (it doesn’t, but let’s pretend it does) it would be called CLUSTER.tnm_staging_v7.v1, and its successor would be called CLUSTER.tnm_staging_v8.v1. A good example of this is the OBSERVATION.news_uk_rcp.v1 and OBSERVATION.news2.v1 archetypes.
When we republish an archetype as a new major version, we do so because there’s a breaking change or correction to the same concept. If the concept changes, and a version change of a standardised tool like TNM or NEWS is a concept change, we make a new archetype.
That is very good to hear. It means that most of the problem I refer to doesn’t exist in reality, as long as this kind of discipline is adhered to.
Unfortunately, it doesn’t matter if it’s the same concept clinically, if there are breaking changes, it’s not the same concept technically, and tools expecting the previous ‘shape’ of data will break whenever they encounter the specific breaking changes, i.e. changed paths, data types or whatever.
My original point was that if a sub-part artefact contains breaking changes, so too do all referencing parent artefact - and this is true recursively up an hierarchy of referencing. As I mentioned this is not openEHR-specific; it’s industry-general.
This may seem strange but consider: an archetype is not just a conceptual model of something, it’s a precise technical model of the data items used to record that something in practice. Changing how some clinical element (itself unchanged conceptually) is recorded (e.g. from just String to Date/Quantity/String or whatever) is a new model of how to record that kind of thing.
All consuming software and tools that rely on such details (which is pretty much all UI technology) will consider the ‘same clinical archetype’ with a changed data type (or path, or other breaking change) as a different model of recording.
I’m happy with this distinction. However, we’re not suggesting skipping the major version increment when a breaking change is published. SLOT includes in archetypes are, at least as thought of by clinical modellers, loose couplings. To my knowledge we only have one example where we’ve excluded other archetypes than the one explicitly included from a SLOT, and we’re getting rid of that in an update next week. So in practice, any CLUSTER archetype may show up in a SLOT.
SLOT includes are in practice used as a strong suggestion which in turn is used by tools to make it easier to create templates quickly. The only practical result of the current practice of having to explicitly state the version of an included archetype, is creating more work for editors.
But just note that in ADL2, direct referencing (no slot needed) is easy and likely to be common - it allows pure re-use of shared lower level archetypes. When you said ‘reference’ I assumed you meant a slot of fixed id (which is how to achieve the same thing in ADL1.4); a slot matcher pattern isn’t really a reference. Sorry to be pedantic, but it’s not just for the fun of it - as you know, getting versioning wrong makes everyone hate us
Completely agree, Silje. THat’s been our collective experience and it is working well
The real version commitment comes with slot-filling i.e in templates (and in future ADL2 ‘compound archetypes’, )and that is where the rigour that Thomas is talking about really comes into play.
I haven’t looked at the new changes in AD but I think I agree with Sebastian that the regex generation is not quite right, even if the intent and UX is in the right direction.
Interesting - for me it displays it correctly with the ending “*” as well as the other * whereas for you it displays the v in italics (as indicated for discourse by the two stars). We definitely mean the same thing!


 - complete agreement from me.
- complete agreement from me.