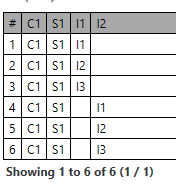
Given the composition on the left, and the AQL query after that, what should the result set for the select clause on the right be? Same as before: think on it whenever you have some free time
The query also looks wrong to me here; the FROM part doesn’t specify a data set that will support the projection c, s, i1, i2.
If we are working on the ‘possible’ basis, then the query will return the row intended, since the instance does happen to support the projection, even if the FROM def doesn’t.
But the logic applied in 4 could also apply here You’re not including those. Again, not to say you’re doing anything wrong, but the interpretation of disjunction when the number of hits is less than the operands of OR (2), the behaviour is different than that of this case, when it is more than 2.
Would you see this as inconsistent behaviour, assuming the role of a developer trying to understand how logical operators work with CONTAINS?
Well the problem with this and some of the other teaser examples is that the FROM part doesn’t specify a data set that can support the projection requested in the SELECT part, so it’s logically inconsistent. I’d be validating queries and tossing out any whose FROM can’t support the SELECT.
I disagree. I’m curious why you think this way but I don’t want to turn this thread into another long discussion about our different views of aql, so I’d appreciate a very brief explanation why you suggest FROM part is invalid.
Well, the FROM part can easily generate a data set that has no i_1s in it, and also a data set that has no i_2s in it. Neither such data set is a logically valid basis for obtaining a projection containing both i_1 and i_2 which is what the SELECT part wants.
If you take the other line, i.e. that the projection is just constructed with nulls where there are no data items, then the question is: what is the meaning of the SELECT part anyway? Is it just: given me any of this that happens to be available from the result of the FROM and null for the rest?
Maybe the mathematically correct view of the view generated by the FROM is the possible shape implied by the archetype slots, not the actual shapes found in the DB.
In DB-land it is different: you can get null results for columns mentioned in the SELECT, but the columns have to be there in the view generated by the FROM, since that is what a ‘projection’ is by definition: a formal sub-set of another set of items (columns in relational calculus).
You’re getting pretty close to my potential answer to your point here so thanks for that
The queries I used in teasers are all valid. They define valid RM structures as constraints, applied to valid composition instances and that’s all I consider in these posts.
How SELECT behaves in relation to FROM’s output is currently unspecified and I’m intentionally leaving that out, though there is an ad-hoc, undocumented, shared interpretation among vendors, as can be seen from the responses.
As mentioned on the thread #1, if we define the SELECT projections validity rules to avoid projecting things that are contained inside each other, we could avoid many of these cartesian product issues, since the issues are really caused by flatting trees. I know we are discussing current state of things, but is good also to think of the next steps for the spec.
On the simplistic argument side I would say to someone that creates such query: "why do you want to project C and I if I is contained in C, so if you already have C you can get I out of it (and any other entry or section).
That argument, also leads to why we have two types of queries in the EHRServer (that doesn’t support AQL):
Composition: only returns lists of compositions that match certain criteria (WHERE), if you want an entry, get the compo and extract the entry yourself
Datavalue: only returns lists of DATA_VALUE, projected from different structures, good for charting and comparing data.
We leave anything in between to the client side (less headaches for me ).
Yes, and we’d make AQL useless in the process. Sometimes cartesian product is actually the correct thing to do: maybe the observations you’re selecting need some context from the section, that will be equal for all of the observations, but restating it in each row is actually semantically correct.
yes - although it seems naively right that you shouldn’t allow containing objects in the same projection, this is exactly the reason we might need them.
The interesting question is at the level of instances - are the S, I, O, E etc just refs into the same value structure as the containing C? In general, I would argue that sub-parts of wholes should always be returned as refs to the data inside the whole rather than copies. Maybe there are arguments for copies though…?
For references, we’d have to define a syntax for each output format (XML, json, …?) as well as handle that in all data consumers (end user apps, query builders with generic row display etc.). Handing over copies is intuitive enough.
Aren’t those two arguments combined strong enough?
I don’t care either way, but how references are done in serial formats use to pass the data from the service is an implementation detail; what matters is that the same structure gets reconstituted on the receiver side as was sent (if it doesn’t, the serialisation/deserialisation is broken). One reason references might be attractive is that you can traverse up and down the one structure as it really is in the CDR. Another is that the amount of network traffic is going to be reduced, and the amount of object copying on the server side will also be reduced. Statistically, this might not make much difference in a real system, I don’t know. It’s just to think about as a straw man.
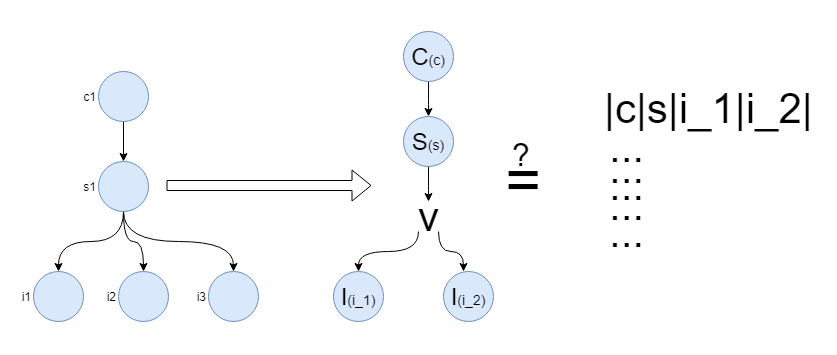
SELECT
c/name/value as C1,
s/name/value as S1,
i_1/name/value as I1,
i_2/name/value as I2
FROM
COMPOSITION c
CONTAINS SECTION s
CONTAINS (
INSTRUCTION i_1 OR INSTRUCTION i_2
)
 You’re not including those. Again, not to say you’re doing anything wrong, but the interpretation of disjunction when the number of hits is less than the operands of OR (2), the behaviour is different than that of this case, when it is more than 2.
You’re not including those. Again, not to say you’re doing anything wrong, but the interpretation of disjunction when the number of hits is less than the operands of OR (2), the behaviour is different than that of this case, when it is more than 2. ).
).