The openEHR SEC has decided on the addition of the required | extensible | preferred | example ‘binding strength’ constraint modifier, following the model used in HL7 FHIR. The change is documented in openEHR CR SPECAM-68.
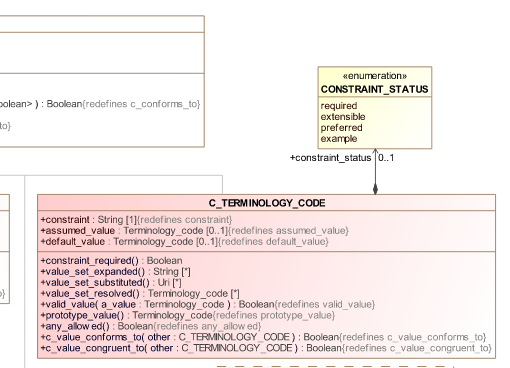
The change to AOM2 spec looks like this in the UML:
We have yet to determine how it should look in ADL2. Currently, the various forms of terminology constraint look as follows in ADL2.
In the above, what appears within the leaf-level {} corresponds to the constraint type C_TERMINOLOGY_CODE, i.e. [at5], [ac1], and [ac2; at23]. We now need a way to modify this constraint to represent the addition of binding strength. Note: the lack of any binding strength constraint is understood to mean ‘required’, i.e. all coded term constraints in today’s archetypes have a strength of ‘required’.
Possibilities could be:
include a strength keyword inside the brackets, e.g. [at5 (preferred)], [at5 | preferred]
include a strength keyword outside the brackets, e.g. preferred:[at5], extensible:[ac1] etc.
something else
I will probably propose the second option as the default approach. The above example would become, with the addition of constraint strengths done this way:
This is terse which is good, but it’s also not very readable. Reminds me of some perl scripts I’ve had the misfortune of trying to decode. I’m ambivalent.
Ok team, question on the real meaning of extensible, preferred and example: it seems to me that extensible has to mean that the supplied code, if not from the value-set in the constraint, is at least from the same terminology, but for preferred, it seems to me it can be from anywhere. This is not stated like this in FHIR, but I can’t see how it makes sense otherwise, to distinguish extensible and preferred - the word ‘extensible’ would not mean what it says.
I struggle with the distinction between extensible and preferred as well, but it feels acceptable to me that an extensible (say international) value set is extended with e.g. local codes from a different . (Plus, the value set could use codes from more than one terminology already.)
extensible just means (to me) that you SHALL only extend the value set if the existing codes in it don’t fit. preferred means you are allowed to replace the whole thing with something different if - say - your local jurisdiction mandates for example the usages a completely different terminology.
Preferred doesn’t have any semantic meaning except being preferred. You might use whatever you like if you don’t prefer the suggestion. As such it has a very low semantic constraint on the model.
I sometimes feel it is better to discuss these constraint strengths less, since every time we do, I think what a bad idea they are
But you are probably both right. I’ll do it like that.
items matches {
ELEMENT[id11] occurrences matches {0..1} matches {
name matches {
DV_CODED_TEXT[id8] matches {
defining_code matches {preferred [ac1]} -- prefer ac1 codes
}
DV_TEXT[id9] -- or plain text
}
then what are the rules for specialising that terminology constraint? Can a weaker ‘soft’ constraint be specialised into a stronger one, but not the other way around? I.e. you could specialise the id8 node into extensible or required? (This would be the a priori approach in ADL - constraint narrowing down the specialisation lineage).
Similarly … for adding new alternative DV_CODED_TEXT nodes, should new siblings in specialised children be limited to only higher strengths? I.e. if you create a required DV_CODED_TEXT, you can’t weaken that by adding any other DV_CODED_TEXT, but if it were a preferred DV_CODED_TEXT, you could add an extensible or required one in a child archetype?
@pieterbos - this is getting into the new validity rule(s) we are thinking of - see what you think.
These are the current FHIR definitions - I think they are fine. It does allow extensible valuesets to be extended with a different terminology, as long as that does not conflict with an existing code. It also allows for free text, which we are proposing to handle a little differently.
This is not about pure semantics, it is about negotiated conformance. but I agree that it should not be possible for a specialisation to weaken the level of binding.
However, I don’t think we should try to enforce this in validation (even if we could) , just make the normal ‘rules of the road’ clear.
To be conformant, the concept in this element SHALL be from the specified value set if any of the codes within the value set can apply to the concept being communicated. If the value set does not cover the concept (based on human review), alternate codings (or, data type allowing, text) may be included instead.
Instances are not expected or even encouraged to draw from the specified value set. The value set merely provides examples of the types of concepts intended to be included.
Well, anything but required will be treated the same as a constraint that simply says this node is a Coded term of some sort, but nothing more. The constraint specification for these case will be ignored by any archetype / data processor implementing ADL/AOM. If some higher level validator / checker wants to do something, that’s fine but it’s outside ADL scope.
From a tooling POV is it not the other way around? The current default for an internal codeList is that it is non-extensible. ‘required’ is the current default. The special handling is when the modeller loosens the constraint and this can be used to advise tooling.
But I think I understand re out of AOM/ADL scope. I’m fine with that.
We can decide the default semantics we want. Not specifying a constraint usually means “whatever rm says”. In this case, probably current behaviour (i.e. Required) should be the default so we don’t break anything
If my statement was unclear, I meant: required is the default; for any other strength, any value-set or value (ac-code or at-code) that is set in the constraint is just ignored, so this is the same as if the constraint just said: this node has to be a terminology code, with no constraint at all on the value.
I have recently stumbled upon a new HL7 FHIR addition, to be able to better differntiate in binding strength, by adding additional value set that can have different puposes to the base valueset:
New records are required to use this value set, but legacy records may use other codes. The definition of ‘new record’ is difficult, since systems often create new records based on pre-existing data. Usually ‘current’ bindings are mandated by an external authority that makes clear rules around this
This value set is provided for user look up in a given context. Typically, these valuesets only include a subset of codes relevant for input in a context
It is still only a nightly build, but I think it solves some of the weaknesses of the extensible binding in creating some possibilities to constrain extensibility as well as add more differntiation for use cases (e.g. in templates). I think this could be very usefull for openEHR as well.
I’m totally ignorant about this area, so I’ll ask: is there anything to represent “not extensible”? extensible seems to indicate a property a code could have, so if it could have it, it could also NOT have it, if that is the case, how can that be expressed?
In the case of required and preferred since those seem to be boolean, the absence of those might read as NOT, but it’s not clear on the case of extensible.