In rest api specification, composition has a ‘PUT’ update but without ‘PATCH’ update, does it means it produces redundant storage even I only change little in a huge composition?
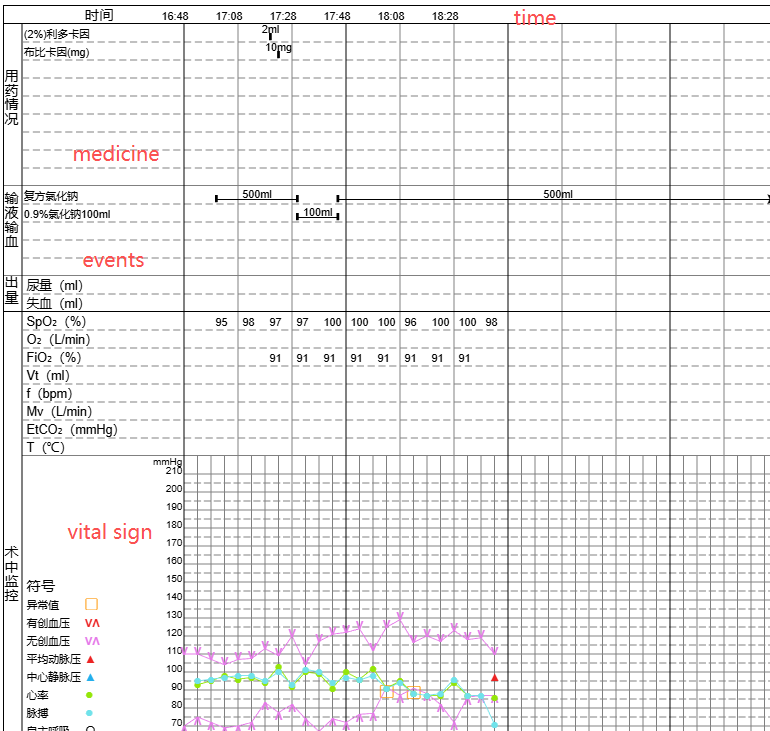
In my case, a clinical document contains medication records equipment data, and much more other data during surgery, all of which are dynamically updated. The entire document spans a considerable period and has many changes. I’m not sure how to handle this in OpenEHR.
openEHR is technology and implementation agnostic, or is supposed to be as much as possible. This is to avoid a standard that is strongly coupled to a particular technology. There has to be compromise though, and Implementation Technology Specifications such as REST is how we do this balancing act.
The reason I’m sounding a bit pedantic is to make the point that your concern about storage remains on the technology agnostic side of openEHR. REST is an interface technology. PUT vs PATCH semantics differ in terms of idempotency, data scope of the update (whole vs changes) etc but how the actual storage of data is implemented is not REST’s concern.
How the actual persistence is handled is the choice of the platform implementer. We cannot surface this to REST specs either, because then we’d be making assumptions about how the interface is implemented, and the whole point of having an interface is to not to dictate how it is implemented
In short: you should not be concerned about this, or think about how to handle this in openEHR. It is very kind of you to have that concern though, so if you think you’ll be piling a lot of data, talk to the person in charge of your platform (CDR especially) about this. We use simulation to estimate disk usage, computing requirements etc in Ocean. I presented this in Barcelona, I’m assuming recordings will emerge at some point.
If you are the person who needs to figure this out, check out how synthea works for simulating data, it is a fhir solution but you’ll see the concept.
I’ll stop speculating now. I hope the above helps.
@Seref@borut.jures I feel my previous explanation wasn’t clear. To be more specific, for example, if my document has 5 parts, but it wasn’t written all at once, then based on my current experiment using components in ehrbase, when saving, it will generate 5 historical versions sequentially, like this:
1
1 2
1 2 3
1 2 3 4
1 2 3 4 5
That means O(n^2) space occupied by increases with the growth of n. In my case, n > 200 probably.
I thought one document corresponded to one template/composition, but this seems to increase storage space too much. Am I misunderstanding the usage of composition?
Your screenshot gives very valueable context information! I would definitely split this into multiple compositions, maybe even separate compositions per vital sign measurement, medication action or other event. One way of linking them together to give the overall context of a single surgery could be to use folders, but actual technical implementers will know more about this than I do.
I would definitely split this into multiple compositions, maybe even separate compositions per vital sign measurement, medication action or other event.
I agree. I also guessed that it could be done using a “folder” or, as you just mentioned, by “compound composition”. I initially thought this was a common scenario, but I couldn’t find official guidance.
Another related question is whether openEHR is still suitable for storing data streams, such as vital sign data retrieved from devices. My main concern is performance.
I’m not sure how a stream would be handled in practice, but my gut feeling is that the full stream should probably be kept in a specialised and maybe short-time storage of some kind, while only exerpts deemed “documentation-worthy” (or something like that) would be kept for posterity in the openEHR record.
So rough guide on our approach, pretty close ? identical to Silje..
One Vital Signs template - multiple composition instances for each recording event
One Medications /fluids administration template using ACTION.medication, with a separate composition instance for each ‘event’ i,e bundle up meds/fluids given at the same time.
I would not use openEHR for streaming fine-grained data - the Observation class is well-designed for this but, as you say, there is potentially a huge data load.
Maybe ask this as a a separate question - I know it came up as a topic at the recent Highmed Bar Camp and there were people with some practical/academic pexperience.
I’m going to repeat my point from above: openEHR is just the specification. Whether or not it is capable of representing the clinical data for vital sign data from devices is a different question than whether or not a particular implementation of openEHR will provide the expected performance.
If you have concerns about the performance of EhrBase (which is the implementation you appear to be working with), you may want to generate test data and observe performance of storage, querying etc. It may or may not live up to your expectations, which are inevitably subjective: the amount of computing resources you’d need to allocate (pay for) to achieve the performance you consider sufficient, whether or not EhrBase can scale vertically if you give it more resources, how it’ll respond with data growth.
You are referring to default versioning behaviour of openEHR above: most CDR implementations keep a single version of a composition as a standalone record, which is a design trade off. So you will indeed have 200 records/documents/blobs etc for 200 versions.
You may consider working around these constraints by considering suggestions from others in this thread, such as not using openEHR for all versions of your data etc.
On a separate note, I’m curious about your computing use-cases. Do you need to compute over all versions of your device data? Are there interim and meaningful versions of the data? Do you need aggregates of values across the whole stream? etc etc.
I would expect a specialised type of storage would be required for properly utilising the HISTORY class for this? Otherwise you might have to save up a million (literally!) POINT_EVENTs before committing the (huge!) composition, and in the meantime there’s no meaningful way to query the received but not yet committed data?
Exactly. In the same way that medical images are not stored directly in the CDR but in a specialized PACS, real-time or near real-time streamed data should have their own storage. Only the clinically relevant data points should then be extracted into openEHR.
I would do the same as @siljelb suggested. Store raw binary data (stream) separately, summarize clinical meaningful results in a composition (or multiple ones). You could also embedded binary raw data into compositions (as DV_MULTIMEDIA or DV_PARSABLE), but I would assess carefully if that’s actually needed.
Or as you suggested before, compress the fine-grain data into a set of average interval events with significant point events being retained.
@Reto - I think you mentioned you had some expertise in this area of data compression?
and to re-iterate what @Seref said, openEHR does not itself specify that whole compositions need to be committed, That just happens to be how most current CDRs are designed - other internal variations are perfectly acceptable as long as the data logically appears correct when it is surfaced.
At the API level, yes, you need to send the full COMPO with the changes if you are using the canonical openEHR formats.
The current API doesn’t formally support PATCH for partial updates.
In the repo, after receiving the full COMPO, you can either store the whole thing, or do a diff with the previous version and store only what changed (delta store). That part is up to you, openEHR will not tell you how to persist the data.
Did you consider storing the intermediate versions as “incomplete”?
Then the final version can be the “complete” one.
Depending on the storage implementation, an “incomplete” could store a new version or you can choose to just keep the new one, since the “incomplete” state means this will be modified several times until completed and maybe managing “incomplete” versions might not make much sense in this case.
Note how that is managed and stored is all up to the implementation, the openEHR specs will not tell you actually HOW to store things.