If you want an extreme example, see the HL7v3 Act and ActRelationship classes - 22 and 18 attributes respectively. They could never adequately define the rules for what values were allowed in each field, depending on what values were in other fields, or when optionality applied. The interdependencies make it impossible. It’s only possible to do it when the class represents a coherent type all of whose attributes relate to that type and not either semantic parents, or composition sub-parts.
Industry activity suggests otherwise But I know what you mean. However, openEHR RM isn’t trying to be anything other than a coherent canonical model of data in patient records. The main thing I regret was not using more generic types, because I didn’t realise that Java etc would eventually get them kind of right (even if they do evaporate in byte code). Then we could have had things like Measured<Quantity>, which would have been very nice. Inheritance is already pretty minimal, and about the same as in other typical industry models.
Agree on various data projections, but to have projections, including models optimised for data retrieve, we have to have the original model to generate from. Starting with projections is very risky.
I’m not aware of anywhere where the amount of inheritance is a problem. Whether we got every inheritance relationship (the DV_TEXT / DV_CODED_TEXT example) is a question. But the inheritance doesn’t seem to cause any problems generally - maybe the DV_ORDERED part of the model could be easier. But we could achieve that by things like Measured<> which would move all the accuracy and related fields to the right place. Indeed, the current Quantity classes are in fact a good example of the flattening/ mixin problem, created by us (mainly me).
I think the problem is less the amount, more the way some classes are inherited at least in this case. Surely I dont know about the rest of the RM, as you guys do.
Thanks i already read that, i just do not 100% agree with that design choice
Thats exactly why it has the “issues” described above with naming and cardinality, at least in my opinion. But there are also valid points in doing it like that as you and thomas already stated.
Realising that I am bit late to the party, I won’t go into a philosophical discussion, but want to quickly voice my opinion here:
Inheritance in openEHR feels about right to me, generally speaking. (If ever redone, some streamlining may be useful).
The generic types approach Thomas mentions would have been nice, but too cumbersome for tooling at the time
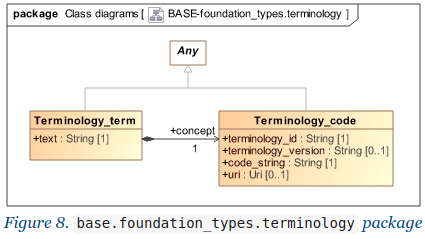
DV_CODED_TEXT is a trouble maker as can be seen with this renewed discussion
I used to agree with the idea of having the DV_TEXT text value mandatory and believe it was the right design choice at the time. However, nowadays you can consider e.g. Snomed CT and LOINC almost as a commodity and this changes the balance somewhat.
I can see why Thomas disagrees, but - from my (in this case) maybe rather pragmatic perspective - the FHIR guys got CodeableConcept pretty right. Leaving the difficult question of legacy data, potential migration, multiple ways of expressing the same thing, etc. aside, I think a CodeableConcept-ish datatype would be useful.
Not sure how exactly Ian sees the CodeableConcept facade working in practice, but maybe this is something to be explored further.
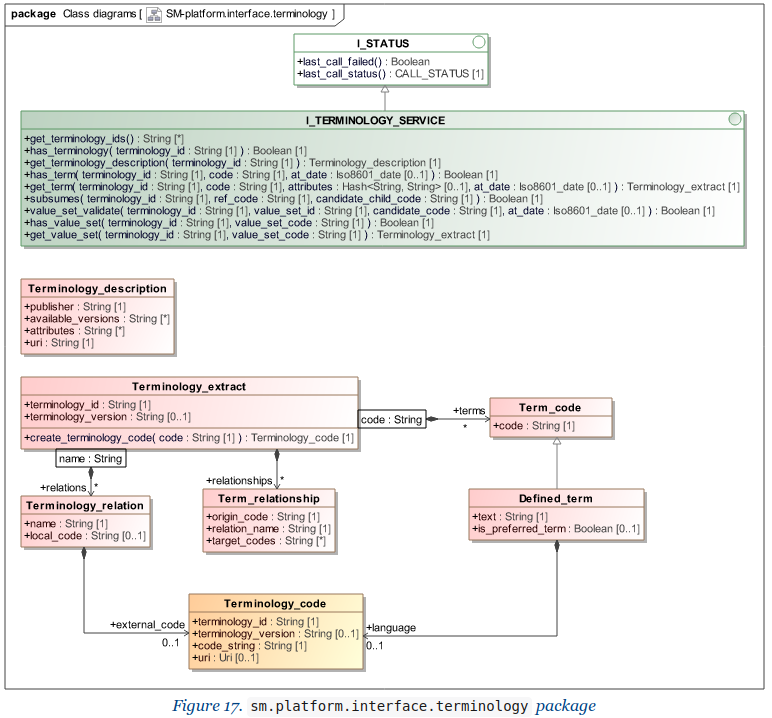
In this model, we can see a field ‘userSelected’. This demonstrates the factoring of FHIR types as being designed for clinical data retrieval - contextual attributes such as this are mixed in with definitional attributes. In a canonical model, you would never do this. The correct name for the Coding (based on its attributes) type would in fact be something like CodingUsedInData. It is easy to imagine applications that want to use this type, but could never populate this field, for the simple reason that there are numerous places in models and applications you want to represent codes that are not captured via user entry.
Indeed, FHIR-based app developers are doing this all the time, and have to skip past this field, and make sure no software reading the Coding object does anything wrong…
I remain very comfortable with having value as mandatory - we do come across occasional instances of ‘technical codes’ where there is no formal text value , though the code itself may be human readable. In that case I simply advise replicating the code as text.
re CodeableConcept - I agree that the ‘display’ is badly termed - it should be (and I suspect is often taken to be) what we would call the defining_code. Nevertheless having all of the assigned codes in a simple list, with the ‘source of truth’ failed is way easier to understand, than explicitly separating the mappings as we do.