Digging through the docs, I can now see that the underscore = ‘optional RM attribute’ might well be the case
It doesn’t sound like a good idea, for exactly the reason you mentioned just above - the usual interpretation of such names is they are some special / meta / pseudo attribute…
We have looked into this a bit more today and had a few more observations (especially when we hit yet another problem, now with /context/other_context !)
Our theory is that at some level (generating a Web Template? or maybe in other places as well?) there is an intrepretation happening where, at a minimum,
- “/category” is expected to have a DV_CODED_TEXT child without node_id specified
- “/context” is expected to have a child EVENT_CONTEXT without node_id specified
- “/context/other_context” is expected to have a child ITEM_TREE with node_id = at0001
It seems like this is generally the case for many of the different specialized Composition archetypes but not for all of them, and especially not for some of the “newer” ones that we are looking at.
For example, openEHR-EHR-COMPOSITION.report-result.v1 seems to follow this pattern, but not openEHR-EHR-COMPOSITION.self_reported_data.v1, which instead looks like this:
- “/category” has a DV_CODED_TEXT child with node_id at0001 (instead of blank)
- “/context” has a child EVENT_CONTEXT with a node_id at0002 (instead of blank)
- “/context/other_context” has a child ITEM_TREE with node_id = at0003 (instead of at0001)
And then when these kind of differences happen, we don’t seem to get the “normal” paths for these nodes in the Web Template, and then have this problem/confusion when we try to write compositions and build more standardized tooling.
@thomas.beale Does it seem right/ok to have different node_ids for these different specialized Compositions (e.g. sometimes other_context can be at0002, at0003, etc) or does it seem more that all types of compositions should follow the same pattern when it comes to node_id for these nodes?
And as a follow-up question, does it seem reasonable that we should be able to expect for example to “always” write to /context/ and /category (etc) in FLAT format, or that we should instead expect to get different paths for these in every new Web Template (depending on the template itself and its own node_ids)?
Hi Joshua,
I’m pretty sure (and confirmed with @borut.fabjan ) that this is simply down a change made to AD when creating new compositions.
The atCodes on /context and /category are not required, but are legal in ADL, but the main problem was that when the related terms were generated, they were added as ‘Event Context’ not ‘context’ , and as ‘DV coded text’ not as ‘category’.
In any case, I would argue that the web template generator should ignore any non-LOCATABLE name overrides, since these never find there way into the CDR data.
- “/context/other_context” has a child ITEM_TREE with node_id = at0003 (instead of at0001)
This is correct and simply reflects that the archetype has had a slot constraint added. The ITEM_TREE atcodes will be inconsistent across archetypes and this is normal and expected.
I don’t think the specialisation is causing any issues here. and I’m pretty sure the confusion is wholly down to the combination of the redundant atCodes being added to ‘context’ and ‘category’, the incorrect terms that were being created, and finally the web template generation picking up these terms, when they should be ignored.
Can somebody with enough CKM privileges (@sebastian.garde, @siljelb or somebody else?) then please patch and re-release that self_reported_data.v1 archetype to remove those two extra at codes for /category and /context and perhaps somebody could also later scan through other COMPOSITION archetypes edited ~last year to see if the error has slipped into any other archetype.
I have just uploaded a ‘fixed’ self_reported_data composition as a change request on CKM.
That is the only published archetype on CKM that is affected as far as I can tell. There are 3 other non-published archetypes with the same issue
I think there is an open question on whether this is, or at least should be regarded as, a breaking change.
On the one hand, strictly speaking, this is not breaking change since the extra atCodes have no impact on run-time / persisted data, this is really an issue only for design-time tooling. OTOH, given the confusion potentially being caused in folks who use web templates and FLAT formats, there is an argument for bumping it up to v2. @sebastian.garde ??
The other compositions (all unpublished) are
Obstetric history, Draft archetype [Internet]. openEHR Foundation, openEHR Clinical Knowledge Manager [cited: 2023-04-17]. Available from: Clinical Knowledge Manager
Advance care, Draft archetype [Internet]. openEHR Foundation, openEHR Clinical Knowledge Manager [cited: 2023-04-17]. Available from: Clinical Knowledge Manager
Certificate, Draft archetype [Internet]. openEHR Foundation, openEHR Clinical Knowledge Manager [cited: 2023-04-17]. Available from: Clinical Knowledge Manager
Disease surveillance, Draft archetype [Internet]. openEHR Foundation, openEHR Clinical Knowledge Manager [cited: 2023-04-17]. Available from: Clinical Knowledge Manager
Note that I had to edit the ADL outside Archetype designer to make it ‘stick’.
That can’t be a general rule, it simple doesn’t happen in all archetypes.
Options are: instead of ITEM_TREE, to have ITEM_TABLE, ITEM_LIST or ITEM_SINGLE.
Instead of at0001 you can have whatever at code, like a specialization could have at0001.1, just to show one example.
So that couldn’t be what is expected for any data structure, that should be expected only for the structures that comply with that, based on the referenced template/archetype.
That is true Pablo but we agreed (us modellers) many years ago to only use ITEM_TREE and the current AD does not give us the choice (by agreement). There are no CKM archetypes that have other structures now
As you say, the actual atCode is not significant.
I know Ian, though
-
not everyone is using AD, in fact other modeling tools allow other structure types, and I can build my own modeling tool that is compliant with the specs and implement all the types;
-
even if the international CKM doesn’t have other structures than trees, that doesn’t prevent other modelers to use other structures, the only way this holds from the spec compliance point of view is that the other structure types are removed from the RM, which won’t happen any time soon
-
archetypes and templates created on other modeling tools can still have other types as structures, then data will go with those types to the CDR, then if the CDR doesn’t allow them, it’s a compliance thing of the CDR, it doesn’t support the types, which should be stated in the Conformance Statement (defined in the conformance framework CaboLabs Blog - openEHR Conformance Framework). Not publishing that info would mean users of that CDR might want to use something that is not supported. It will also mess the conformance verification because it will lower the conformance score for that tool by failing the tests associated with different structure types.
The real issue is agreeing on a usage thing while the specs are not updated and older ones deprecated. Note that as an interim solution is OK but shouldn’t be a long term thing. In fact we should be already working on updating the RM DATA_STRUCTURE model.
I believe @ian.mcnicoll’s comment in the CKM gives good context and explains some things tings in more detail than some of the posts in this thread, so here is a screenshot:
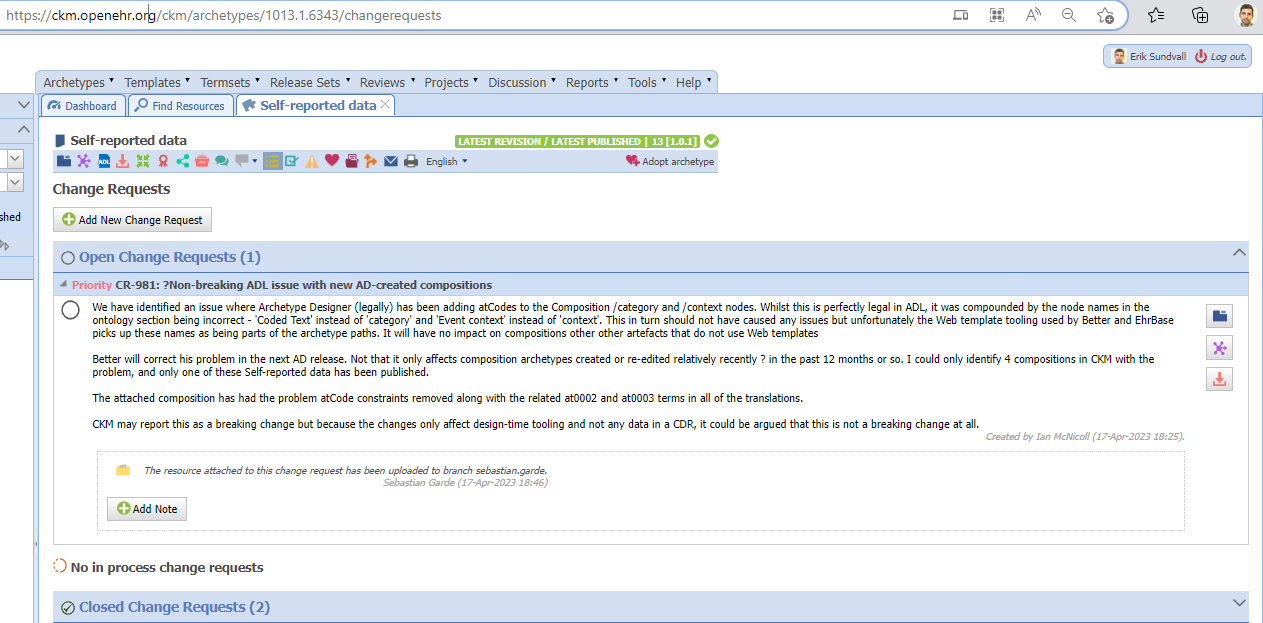
Well, if this has no chance of having ended in data, I am torn…it is a matter of definition (of what it has to break to be considered a breaking change). But let me clarify, is there really no chance that the now deleted at0002 code / a path containing it could have ended up somewhere in data? If there is a chance, I would expect at0002 to remain present even if it is not particularly meaningful.
The archetype self_reported_data.v1 is pretty new, so an early breaking change now is better than keeping any of the errors in the archetype. (Especially since the errors cause really bad errors downstream in many tools and platforms as described in this thread)
Also a breaking change can better signal that there was something seriously wrong with the archetype, and that you really need to think through differences and the suitability of any possible continued use of the (then) old v1.
At Karolinska we will soon start using it for real patient data, so an internationally agreed complete fix of the broken archetype would be very nice to have in the CKM (instead of us fixing it locally and risking doing something different than what will finally and up in the official CKM archetype).
I think it would be good to fix the draft archetypes that Ian listed too fairly soon, but since they are not yet published the exact choice of what version-position to bump up is of less importance.
I have tested both EhrBase and Better, and in neither case do the redundant atCodes appear in the canonical data, or cause any other apparent issues.
"category": {
"_type": "DV_CODED_TEXT",
"value": "event",
"defining_code": {
"_type": "CODE_PHRASE",
"terminology_id": {
"_type": "TERMINOLOGY_ID",
"value": "openehr"
},
"code_string": "433"
}
},
"composer": {
"_type": "PARTY_IDENTIFIED",
"name": "ISO_3166-1"
},
"context": {
"_type": "EVENT_CONTEXT",
"start_time": {
"_type": "DV_DATE_TIME",
"value": "2023-04-19T09:21:38.415Z"
},
"setting": {
"_type": "DV_CODED_TEXT",
"value": "other care",
"defining_code": {
"_type": "CODE_PHRASE",
"terminology_id": {
"_type": "TERMINOLOGY_ID",
"value": "openehr"
},
"code_string": "238"
}
}
},
So I think the argument for the breaking change is really as an alert, rather than that it is technically necessary.
From our perspective what seems to “break” is that we have a template based on openEHR-EHR-COMPOSITION.self_reported_data.v1 where we have added some stuff under /context, and if we make a local copy of this new 1.0.2-alpha revision (but still using the same Archetype ID, openEHR-EHR-COMPOSITION.self_reported_data.v1), then when we try to open said template in Archetype Designer, there are two warnings which pop up:
- Template depends on archetype openEHR-EHR-COMPOSITION.self_reported_data.v1 which may have changed since this template was last saved. Template expects integrity hash: 782C49493E523506E8C34B7C5CF7B761, but actual: 8ce513a50cfa52112d9d79313e52cbf7
- Constraint node at [openEHR-EHR-COMPOSITION.t_self_reported_data.v1/context[at0002]] specializes a constraint missing in parent archetype [openEHR-EHR-COMPOSITION.self_reported_data.v1] and was removed during flattening
The first warning is fine/expected, but the second one is where we have the issue – everything we had added in the template under /context has actually disappeared and I assume we will need to add it all back manually? Is this considered a “break” that could be served better in some way by rolling to .v2 (which I am assuming means we actually need to rebuild the entire template over anyway?) or is there a better way to handle this issue? (which we don’t necessarily need to take in this thread, more a question of if this important to consider when deciding if an archetype change is breaking vs non-breaking)
Thanks Joshua,
This is a good point. I had not considered the potential impact on a template which had constraints or slotted archetypes inside context/other_details.
As you say, the impact of going to v2 is even more disruptive.
There may be a way of editing the native json template files to avoid having to recreate the lost items manually.
It gets a bit more interesting actually: I just found that we were not even able to add it back manually with Archetype Designer in this case; I actually needed to manually patch the JSON file outside of Archetype Designer (Manual patch ChemoForm-MBA.v5.rc14 to add context · regionstockholm/CKM-mirror-via-modellbibliotek@c2be87e · GitHub) to get our extension back after the node was deleted from the template in AD. The “plus” button did not do anything and the list on the right side to search and add Archetypes would not appear under /context so it felt a bit “stuck” unfortunately ![]()
But now it seems “ok”! So we will do some exports and start to try this out and see how it goes with all of our various components.
Yes I just managed the same.
THe process is
- Export the affected template using the native json option and open this in a text editor, search for EVENT_CONTEXT then remove the adjacent
"nodeId": "at0002"line.
The ‘category’ attribute is not included in the native json template so there are no other edits required, as far as I can tell.
-
Import the corrected version of the Composition archetype, which has had the erroneous atCodes and terms removed.
-
Import the corrected native json template, making sure you allow overwrites.
@joshua.grisham made a release of our current approach today (based on @ian.mcnicoll’s patched archetype) for those that are curious: Release ChemoForm-MBA.v5.rc14 · regionstockholm/CKM-mirror-via-modellbibliotek · GitHub
I believe the original problem when creating new compositions is now fixed with AD 1.2.47