
Agree, “Description” can be used that way, but not always., They definately can, if the archetypes are spesific for one purpose, or made for local use. We’re reluctant to make the published archetypes into text-book-like instructions on how to use or interpret the various elements in, for example a scale or score. Both because it’s not the task of the modelleres to teach end-users clinical knowledge, but also because this opens for discussions on the concept (or scale/score) itself. We try to be neutral and only define as good as possible WHAT the element is, and not as much HOW it to be used in a clinical setting. Otherwise we might introduce possible erronous use or interpretation, causing medical harm.
In this case I regard these as UI guidance - if 80% of the items have no associated text, that is not a scale IMHO of course 
That’s a reasonable approach. Templating with ADL2 will make this easier as we can create template-level codes with associated 'local descriptions and comments where the underlying archetype descriptions are not fit for use as user-tool-tips
1 Like
This worries me. As modellers we have a responsibility to be so careful - to be faithful to the original intent as much as we can, flawed though it may well be. If we make unilateral assumptions, interpretations, best guesses or ‘fudges’, we start to create a divergence that can potentially become amplified as a clinical safety issue in implementation.
2 Likes
That’s a very fair point , and as a principle I’d agree but I’d also argue that there are situations where a scale/score designed on a paper form (often rather badly) does not safely transfer to digital implementation without some tweaking. I agree we should not do that lightly or randomly but nor do I think we need to replicate something developed for paper often as an academic exercise with very limited real-world use, which will have been tweaked in the world as people have tried to implement it.
We have seen that already with GCS, possibly one of the best and least contentious scores. It does not translate safely into non-paper use without some tweaking.
Interesting but important philosophical discussion.
Practically speaking it may be difficult to drop the mandatory text requirement without causing quality issues elsewhere but I’ll take it back to SEC. At worst we could just use a space character.
I’m actually more concerned about allowing scale items without a value - do you have some real exapmles we can look at. The only one I know of is the ‘Spinal Tap - turn it up to 11’ Borg CR10 scale
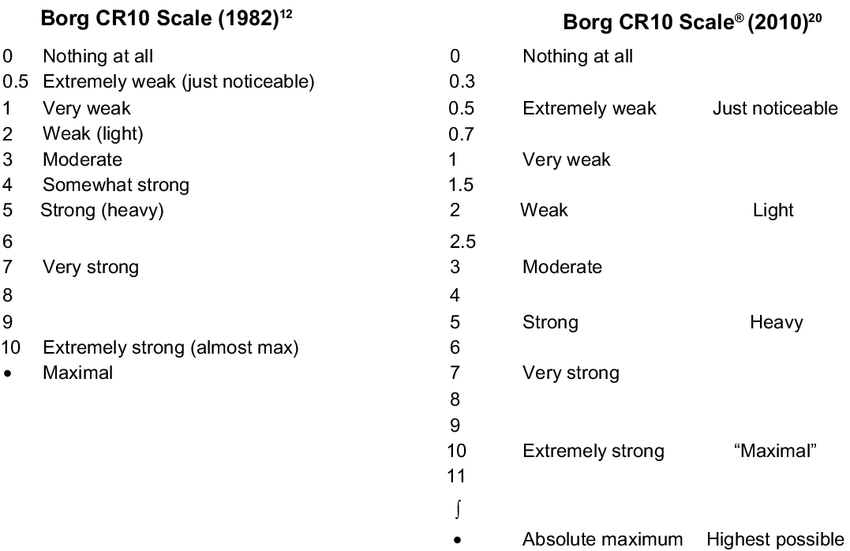
I would model that as an Ordinal/Coded_Text choice, although actually it is nonsense IMO.
Positive. 
Maybe we need a reference standard (e.g., LOINC, CIMI) for domain modelling.
LOINC Answer List Example
LOINC LL3509-8 — UPDRS_Intellectual impairment / Answers: 5; Scale: Ord; Code: 0-4; Score: 0-4
THat is a slightly weird mix of LOINC and SNOMED noInteresting via the LOINC definition I found this for the Borg scale (that has missing text in the original).
https://cde.nlm.nih.gov/deView?tinyId=T96cTBoIo
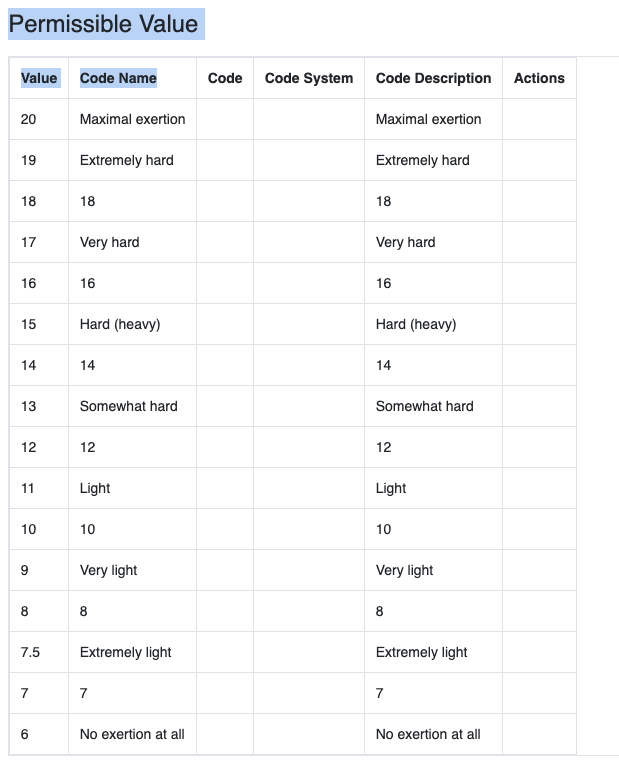
versus the LOINC version that uses blank text
and Silje’s example
Looks like I have supporters but not in LOINC!!
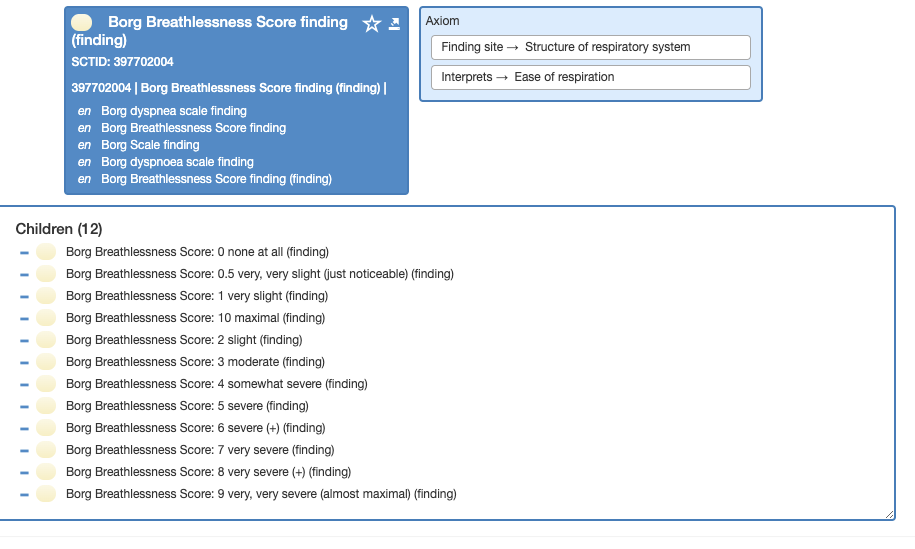
SCT FSNs are more descriptive
Requests for improvement could be submitted to LOINC Committee if you’d like to contribute.
Need to be a bit careful here. DV_ORDINAL & DV_SCALE have a symbol field of type DV_CODED_TEXT, which has no ‘description’, only a value field (as you are used to). Spec link here.
Coded entities, i.e. object nodes and value-set values (= id-codes and at-codes + ac-codes in ADL2) are all a generic ARCHETYPE_TERM, consisting of at least code, text, and description fields, and any others you want to add. Spec link here.
The model of the symbol field of a DV_ORDINAL or DV_SCALE is of the first type - they are coding actual runtime data values (e.g. ‘not present’ | ‘< 100 bpm’ | ‘>= 100 bpm’ or ‘+’ | ‘++’ | ‘+++’ etc). The id-codes used on the ELEMENTs of the various score items (a la Apgar, Barthel etc) are of the second type - i.e. they are naming what the model items are (e.g. heartbeat, muscle tone, …).
So those ARCHETYPE_TERMs are our simple model of terminology as it exists in archetypes and templates, used for identifying parts of the archetype, and also defining value set items.
We could in theory make ‘description’ field optional without breaking runtime data, but it would probably break most Archetype modelling tools. I’d be more inclined to keep it mandatory, and have it set by the tool to some automatic string, where the modeller doesn’t want to fill it out. In the simplest case, an empty string (always guaranteed to cause confusion later on) or better, some machine-processible string like ‘[=text]’ or whatever you really need there.
1 Like
I think we are clear that description only relates to the term inside the ontology section of the archetype/template, and does not appear in the patient instance data.
Why should making it optional cause issues for tooling vendors? Right now, what happens is that when a new term is created a ‘dummy’ description is generated as “*”. All that needs to happen is for that to change to an empty string and for any validations on description to be relaxed.
Clearly there will need to be a bit of coordination esp between AD and CKM but that is just about timing of relaxing the constraint. @sebastian.garde @borut.fabjan @yampeku - what do you think?
Managing these descriptions is a particular overhead for translations and certainly in some cases they are redundant.
1 Like
I’m pretty sure this change wouldn’t affect us. We allow empty text and have some logic defined to visualize these archetype nodes even if they have empty (or no) text or descriptions (showing type at least)
We usually try to model the archetype based on the original research as the source of truth, where possible.
And we usually do look at the terminology representation to confirm alignment or as a means to clarify where required. However they often have the same problem - that they need to compromise it to represent it within their structure/display constraints a bit, and we run the risk of propagating the compromise as truth.
It’s a tension that we are always try to balance… but if we do ‘fudge’ it, we try to document it so that others are aware.
2 Likes
description is expected to be there according to 1.4 and 2.0 specs. In 1.4 this is hidden in the text: "For any term or constraint definition, this list must at least include the name/value pairs for the names “text” and “description”. In 2.0 it has been modelled more explicitly.
From my point of view, it is reasonable to relax this but I can also live with the “*” cludge/workaround.
If and when this is relaxed in the specs, we need to look into it for CKM to ensure this works everywhere, including displays, translations, conversions to xml and adl2,…
I don’t suspect major issues, but there will be places where this is checked which would need to be relaxed and where we then need to ensure it is not relied upon.
3 Likes
Well in any software, if the spec says a property is mandatory, implementers work on that assumption - that attribute can’t be void/null. If you later make it optional, any software that followed the previous version of the spec will either keep working (if it creates default values, empty strings etc) or it will break.
An empty string is not an ‘optional’ attribute, formally. An ‘optional’ attribute is one that can be null at runtime. An empty string is just a particular value of the String type.
NB: I’m not saying that moving to optional description will break tools badly; they would probably be fairly easy to update. But there are always unexpected knock-on effects with these kinds of changes. We just need to be careful.
I would suggest a careful examination of the requirements, and decide whether you really want description and maybe other fields to be optional, or if you want them to be mandatory, but defaulted to specific values e.g. empty string etc, in specific circumstances.
There is nothing in the ADL/AOM 2 standard preventing you from setting it to an empty string, so that’s already very possible, just the field is mandatory.
This clearly has some benefits, in the sense that sometimes there just is no description.
It also has some drawbacks, in the sense that this being mandatory forces people into thinking about adding more information to the archetypes wherever possible, and that it is a relatively costly change, because tools everywhere expect this field to be non-null, and tools that have not been updated will then just not work with the newer archetypes.
I have no idea what will break in our software - changing this affects the OPT 2 standard as well, so if this is changed we will probably set it to a default value in the OPT 2 generator wherever it is missing, to not have to fix this everywhere in our code, including form rendering, in the CDR and in applications.
We do also show descriptions in our UI, usually behind a tiny icon users can click on.
I think that definition means that keys must exist, but says nothing about content (can be empty?)
So I guess that might be the easiest compromise - keep Description as mandatory but allow empty strings? I have a feeling that AD behaviour has already changed!! @sebastian.garde will that be easy to support in CKM?