It is a bit confusing, though as @sebastian.iancu points out this is very much work-in-progress.
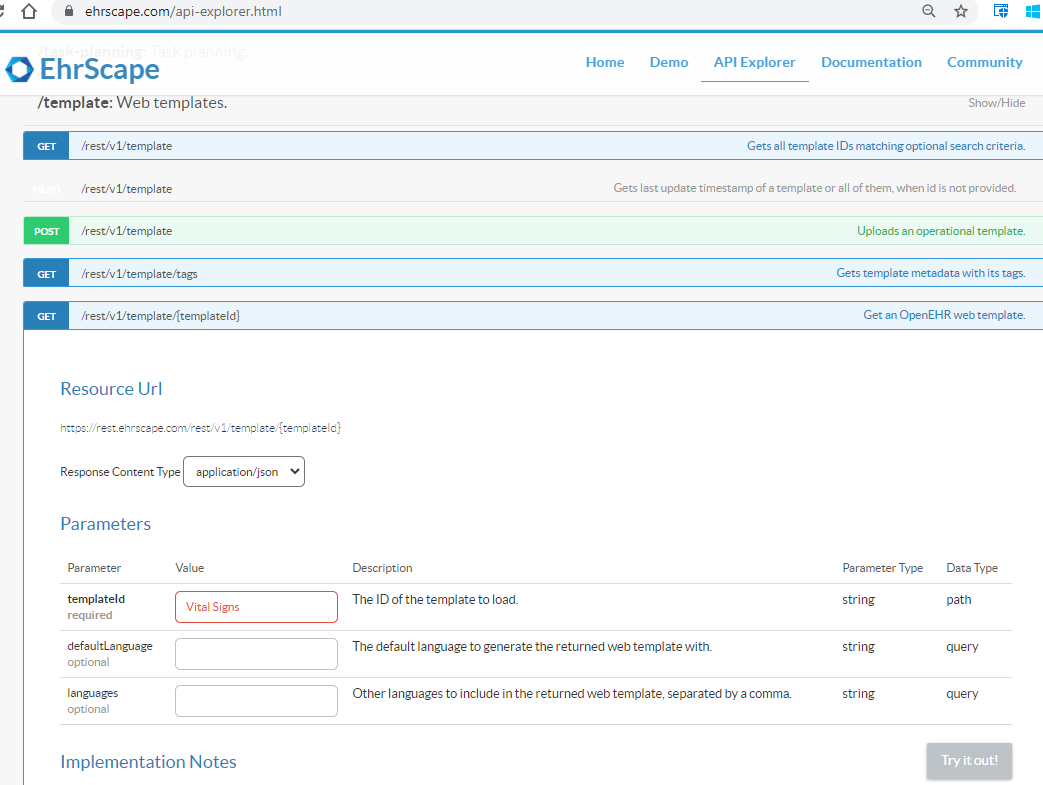
The initial focus, that I think we have pretty well nailed down is to support the current Ehrscape FLAT and STRUCTURED OUTPUT formats via the openEHR Canonical REST API / composition by adding some headers and Content-Types.
I don’t think there will ever be a preferred format as such, and I’m not sure there needs to be.
The ECIS flat format does introduce some nice ideas (and DIPS has something similar) which is using the full AQL-style path for the name and potentially the compact, stringified representations of the values- there is value in these stringified forms beyond composition serialisation - they are useful in GDL etc. and documentation
For now we have probably parked these (I think) as part of the next REST release as this still needs a bit of work.
I do actually like the idea (as you were suggesting) of being able to mix and match the various contracted forms (and including the ability to drop back to RAW canonical json) but that would require something a bit more clever!!
The priority, for me and I think Erik, certainly is to get the ehrscape web template formats supported, then we take a fresh look at new ideas and if we are lucky something even better.
On the last call we also discussed the ehrscape INPUT format (which adds the ctx directives - these are not data items per-se but instructions that help simplify the population of various mandatory items throughout the rest of the ocpmosiiton
e.g ctx/time , unless overriden, ppopulates the context/start_time and every madatory time attribute e.g ACTION.time with the value supplied. This very nice as it removes a lot of boilerplate in the composition. However when the composition is retrieved it is always as the fully populated version so you get a mismatch between the json object sent and the one retrieved.
So while I do use the ctx blocks when training, I tend to suggest that people get up to speed not using ctx, as sooner or later they will are likely to encounter it e.g if working with a persistent composition which needs updated.
Structured or Flat - choose your poison. It’s a cognitive preference, or perhaps JS coders prefer structured because it maps cleanly into their world with out the need to handle the Flat ‘indexers’. As a local organisation or company it might be reasonable to have a specific policy but I don’t think we should express a preference as partof the spec as such.