Well as long as you don’t prevent the addition of other Folders in the archetypes, this will always be possible.
Plus, don’t forget, there are now multiple independent FOLDER trees (there used to be only one, called directory). Whether any particular implem/ product has this depends on whether they have upgraded their EHR RM to Release 1.1.0 / SPECRM-55)
That’s is kind of the sweet spot, having most of the FOLDER internal structure and tree in an OPT without finalizing the structure: allowing additions via extensions to the archetypes inside the OPT and versioning the OPT or in an ad-hoc/custom/runtime way, though those folders added at runtime still have to comply with some archetype and be added to a place where there is an open constraint matches {*} or a slot to that archetype. What shouldn’t happen IMO is adding folders that have archetype ID info and the archetype doesn’t exists (we can’t allow that dummy data in CDRs for is not correct from the conformance standpoint).
So I might be answering myself, but I think CDRs should provide (and maybe we need to have them in the CKM) a basic set of generic/unconstrained folder archetypes to be used on those custom cases. I will try to come up with a basic set.
Note: FOLDER is not even a type in the CKM
I guess we can’t avoid the querying issue: any open constraint is something we can’t use to create a query (we don’t know which paths will exists in data in order to query over them).
I know, just don’t want to add multiplicity to the issue, is just too complex as it is, having discussed a 1…1 case we can think of the 1…* case later.
We had some experience creating FOLDER archetypes (for ISO 13606) around 10 years ago. In that case the objective was not to model the persistence of data, but to have a way to define a view of the EHR in an EHR viewer application. In that context, it worked quite nicely, just as a template to render nodes for each hospital specialty in an EHR tree.
The only problem is that we had to introduce an internal patch in order to point to specific COMPOSITION archetypes from each folder in the FOLDER archetype (the problem of ‘how to archetype links’ previously mentioned by @thomas.beale ).
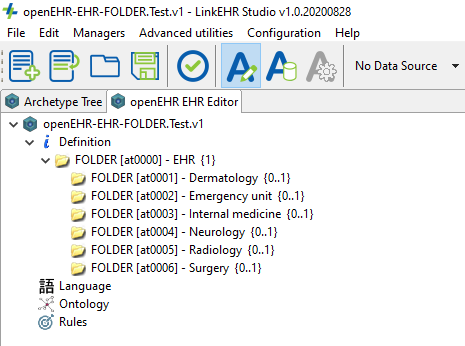
You can try to create FOLDER archetypes in LinkEHR Studio, although I think the FOLDER RM is not completely up to date. We’ll fix it ASAP.
Nice to know that can be done David, bit I’m not sure in my own head if this sort of archetyping/templating is the right approach, as the main value of Folders that I can see (or indeed tags) is that they are multi-hierarchical. There is a definitely a need to document/formalise their use (and indeed higher-level architectures in general) but is current templating the right language?
We are working on a Diabetes care pathway, so we might need to ‘tag’ a composition a s being inside a number of folders
Diabetes care journey
Maybe a folder to represent an admission (if the data is about Diabetes and tan admision)
Maybe another folder to indicate that this is patient-contributed data that has not been curated
And of course a a lot of different variations - so not simple nesting.
@joostholslag@sebastian.iancu - it would be interesting to understand your usage and how you document use. Just not sure that .opt is the right direction.
Defining archetypes/templates for FOLDERS is just a piece of the solution. We could try to solve it by two approaches or a combination of both.
In a top-down approach, we need to be able to define which COMPOSITIONS go inside of each FOLDER. This is useful, as in the project we did, to create dynamic views of data, independently of how they are stored in the CDR. There is where we need some kind of additional reference or slot constraint to attach an archetype id or even an AQL.
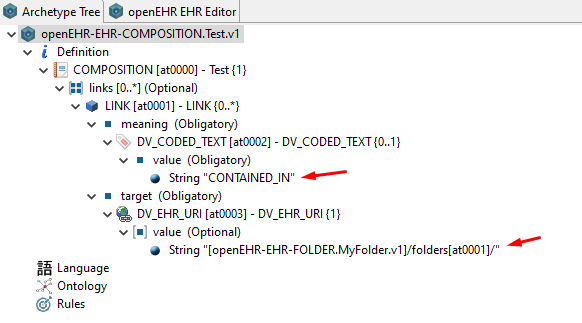
In a bottom-up approach, we need to define in which folders a COMPOSITION archetype will be persisted. This requires a deeper analysis, but a quick and dirty solution would be to have a pointer from the COMPOSITION class to the IDs of the container FOLDERs. Then, during the templating phase, we could define in which FOLDERs we want to put the instances of those compositions. In order to minimize changes in the EHR, maybe this pointer could be just the current LINK. In that case, we need again a method to express a semantic constraint to that link. Note that the following image is just an example of the idea, not a technical valid implementation. Additionally, we could define as many sibling links as we want to solve the multihierarchy problem of FOLDERs.
To get some value out of archetyped folders without having to deal with the tricky/messy parts i still think we should specify and implement/test this in two steps/phases…
…and publish in different RM version releases, where the later step is informed by what we learn from the first.
I may have misunderstood the specific purpose of the suggested backwards pointer, but in general we would not like to change anything inside a (possibly signed) composition whenever we choose to change what FOLDER a COMPOSITION is placed in. Thus pointing to COMPOSTIONS from a FOLDER (i.e. the way FOLDER already works) is more OK than pointing the other way around to define CONTAINED_IN.
Indeed - this is not something you want to do - it makes committed clinical content dependent on someone’s classification scheme. And don’t forget a Composition can be referred to by multiple Folders, e.g. for episode, and also for various research projects or other themes.
Nice @damoca , in fact something like that is what I had in mind, though by the comments of others, we need to keep that structure as “not finalized” so other folders could be added at runtime, though I would prefer to have an explicit declaration of an open constraint that allows to add more folders there but complying with any archetype.
That multi-hierarchy is what kicked my initial question. @ian.mcnicoll for which cases you don’t see archetypes/templates fit? I would like to understand all points, and for me I don’t see a limitation of archetyping folder structures if we mix defined constraints and open constraints in the same OPT to allow flexibility.
This doesn’t seem to be related to the folder structure itself, but to define which items are included in which folders, which IMO should be a runtime thing, not really a modeling constraint.
Another unrelated point we touched some time ago: we would need folders outside ehrs to organize population data (compositions or subcomponents of compositions, from different EHRs inside the same folder). Did the SEC reached any conclusion about this? (I can open a new thread)
We also use FOLDER to “organize” and bind COMPOSITIONs to an Episode, or to a Care-plan; for clinical or administrative info (dates, reason, statuses, providers, etc.) we use a COMPOSITION, also binded to same FOLDER.
We also use FOLDER to “tag” and organize imported COMPOSITION (from associated legacy systems and EHRs). This is not the same as the other support for tags/labels, which is implemented differently; tags can be associated with COMPOSITIONs (actually anythign that versionable).
That might work, but I think there is a lot of overhead - don’t you agree? (trying to reuse a clinical type/sub-structure of a COMPOSITION to persist metadata)
This was a discussion some time ago indeed. You can see it as FOLDERs sits between ENR and COMPOSITIONs, but actually (technically) they sists next to COMPOSITIONs, which they refer to. So the CONTAINS operator is not completely right here - although I can imagine it be convenient/intuitive when you just look to AQL expressiveness. I’m curious about nowadays opinions on this - but perhaps is worth revisiting this subject in SEC under AQL.
If we are able to better constrain a link between folders and compositions (or between any RM class through the LINK or REFERENCE), then we will have the technical basis to analyze how to bring that to the AQL.
The more I think about it, perhaps we should reserve CONTAINS for inline (by-value) composition (i.e. in the UML sense). A new keyword could be used, e.g. INCLUDES or similar that covers by-reference inclusions, as well as what CONTAINS matches.
The idea that CONTAINS is going to start returning matches from referenced items as well as inline data I would say is wrong - we need to be able to distinguish these.
We did discuss that before, and I’d support something like INCLUDES as long as it includes CONTAINS!! I want to be able write queries that are agnostic of the type of association