Hi Sidarth,
I like your first approach with storing the visit ID in other context. However I think it’s not legal to include an archetype there. So I think you’ll have to manually design the compositions in a way that will ensure the paths (including node ids !) are consistent across compositions for reliable querying. Probably think hard about automated testing or similar to find errors at run time, or this can go very wrong. On a side node: composition.context currently is designed only for event compositions and is problematic for persistent compositions (e.g. problem list).
Adding a compostion.meta_data or similar attribute that allows list could solve both problems by e.g. creating a ‘use_archetype’ constraint for a CLUSTER.visit which has a visit_id element. (Current AQL implementations are said to only allow queries on clusters, or you could cut out the cluster middle part and include an element archetype). Issue for the event context for persistent compositions here: [SPECRM-106] - openEHR JIRA
As you already concluded I believe using healthcare facility to store a visit id is misuse. Since the ID is part of party identified to me this is unambiguously the id of the facility (building), not the id of the visit(event). I understand pragmatism is needed in the real world. The risk of misinterpretation for a single systems seems low for the pattern you described.
But since openEHR is intended for interoperability, this will cause real world trouble once you share EHRs with apps that are not controlled by you and don’t know this assumption. (And they shouldn’t need to!).
Slightly off topic I’m also a bit worried about your reluctance to update templates, a minor change like this should be trivial right?
I do feel we may want to support this at RM level. Since it’s such a fundamental usecase most implementers will encounter. And it’s valuable to standardise. And according to reactions from many people, we haven’t solved this one yet.
My first thought would be to add an event_id attribute with DV_IDENTIFIER to composition.context, however this is still problematic for persistent compositions.
@Ohia_George sorry for hijacking your thread, I’m hoping you don’t get overwhelmed by the complexity of our discussion about your straightforward answer. My advices would still be to use folders. But @Sidharth_Ramesh mentioned some important caveats. Let us know if you need further advice, and your experiences in implementing the folders.
Hey Joost,
I agree that something at the RM level would be a great solution.
Regarding my reluctance to updates templates - there are some templates that we don’t have control over. We want to build an “app ecosystem” where each application can have the freedom to model the templates however they like without any restrictions.
A simple example: In India, we have a government program called ABDM that expects FHIR document bundles to be sent for every patient visit to a hospital. We have created an “application” that takes care of this whole integration process. It executes archetype based AQLs to get common data points like chief complaints, diagnosis, medication orders, service orders and multiple observation archetypes and automatically convert them to FHIR resources to send to the government APIs.
So the other applications doesn’t need to reimplement this over and over again and can focus on other specific functionality.
Ideally, we want the ABDM integration application to work with all the other applications as long as they use the right archetypes in their templates and post their compositions to an OpenEHR repository.
Using virtual folders is definitely a workable solution. But when there are multiple applications involved, the problems I mentioned above become a big concern.
What I don’t want is asking every other app to model templates with a specific element to capture the visit id. This will be expensive because there are already many working templates and everyone will need to update them with specific semantics, and also change a lot of application code to reflect these changes.
Pushing it in the context doesn’t require changes to the templates, and can be done at the level of the application, which is relatively quicker and easier.
I think getting the semantics of the “visit” correctly in openEHR is crucial. I agree that the approach we’re taking currently is “hacky” at best. But it works for our situation where changing templates is not in our control, and using folders isn’t practical.
@Ohia_George If you’re just getting started my answer might have provided more questions than answers. I’m sorry!
I think for a use case where you only have your own application using your own OpenEHR data repository, directories are a perfectly fine solution. Being able to query folders by AQL is just a “nice to have” and isn’t really required. You can attain the same functionality using other methods as well.
Well this is potentially true of any attempt to do access control based on content. A fairly common view these days is that viable access control (as opposed to idealistic but probably impossible) is primarily by the record owner (patient) having a way to classify/mark their data as ‘sensitive’, ‘non-sensitive’, and maybe more such classifications. ‘Sensitive’ would require presence of patient to give consent. Emergency situations have a way of over-riding all access control.
We can certainly discuss this, although it was always assumed that that was the purpose of EVENT_CONTEXT.other_context. But if we think we can standardise visit info, more attributes could be added to EVENT_CONTEXT.
In fact you can, but the top-level archetype will either need a slot (ADL1.4) or a direct external ref (ADL2) referring to the other archetype. A new archetype can go anywhere.
That should not be true either - a path in AQL is any path legal in the RM structure.
Yep. No-one is going to expect that…
The problem is: do all institutions have such an identifier for a visit? I don’t think my local GP does. At best the system could construct something like:
or maybe pat-id and doc-id. Internally the various UK GP systems probably do assign a Uid to almost everything, but I doubt if this is exposed in any API or message to the outside world.
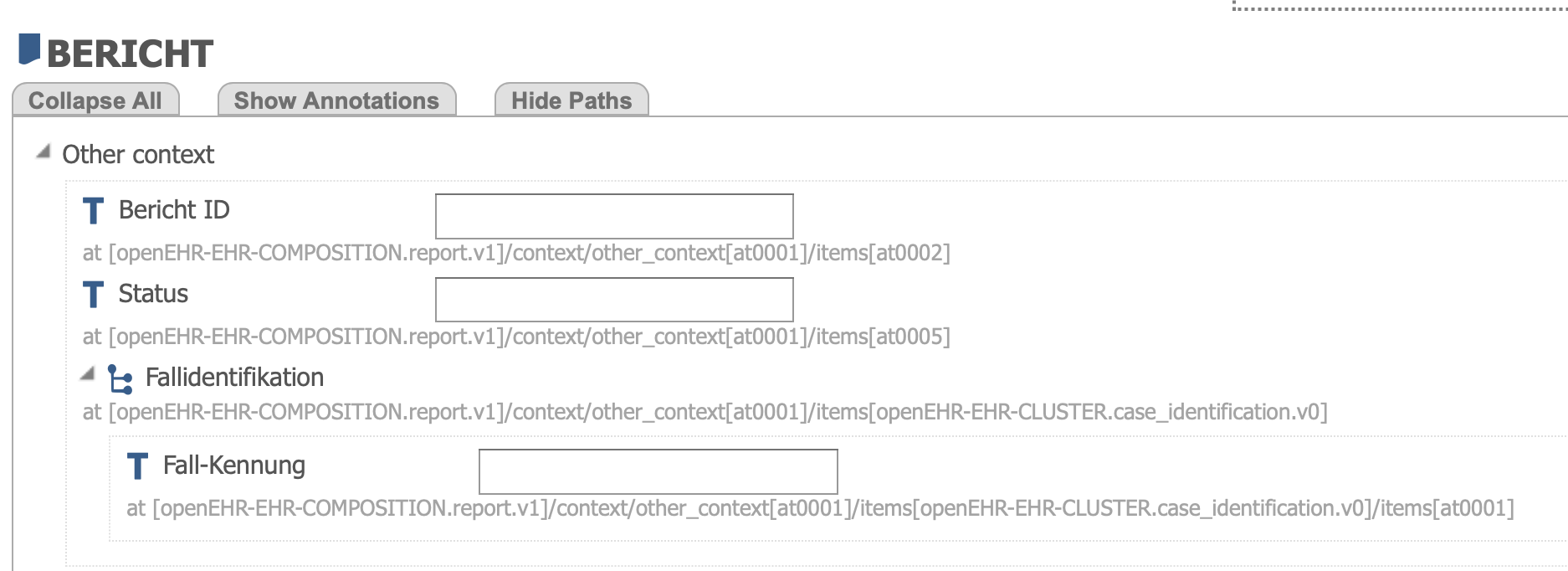
In HiGHmed, we use a cluster archetype “case identification” within the other_context of all templates. No problem at all. I get @Sidharth_Ramesh’s point though. Hence, I think folders would actually a bit more elegant.
I think it’s fine to leave the ‘how to get the ID for a visit’ to implementers for now. It would be good though to have a single space where we record ‘a’ visit ID. I’d be fine with recommending uuid if people prefer it. It will prevent people taking (the wrong) meaning from a numbering system.
From an implementer’s perspective, nearly every system I’ve worked with either has its own visit ID or expects to receive one from a parent system.
The problem is typically too many visit IDs, and a disagreement of the semantics of a visit. For a simple example, if a patient is hospitalized, has a radiology appointment, and needs the pharmacy to dispense a contrast agent that’s potentially three different visit IDs from three different systems, and each care document generated in the workflow will only care about a subset of them.
I think having a standardized solution for visit IDs is very important. It’s often the single central identifier for gathering all data relevant to a particular workflow.
I have faced such differences in the semantics of the visit too. Some hospitals take the entire episode as one visit while some have “micro-visits” that consider different transfers and departments as separate visits within the parent visit.
I like @joostholslag idea of including a field in the EVENT_CONTEXT for the visit id. It’ll be great if it can be 0 to multiple dv_identifiers. That is definitely a possible solution.
Regarding what @birger.haarbrandt said about preferring to use folders, I agree it’s elegant if implemented correctly. Especially since it might be more useful when querying visits within visits.
I’m assuming this is the work flow:
Create a composition
Create or update a folder corresponding to the visit id. Update the parent visit if it’s a micro-visit within the same hospital episode.
Query based on the visit id to get all compositions inside a particular folder. This will be super cool especially if the querying can somehow get all the compositions from a parent visit when taking the micro-visits approach.
Though I’d like to have steps 1 and 2 happen together in a transaction rather than separately. Maybe this is where atomic contributions come to the rescue? Although I’m not sure how that’ll work with simplified data formats like ECIS FLAT.
Great to be having this conversation by the way. Let’s standardise how we represent the visit information at least for new implementations on openEHR!
Adding the feature to tag (or more precisely) annotate compositions with different key,value data. One tag is the EpisodeOfCare . By using this we can add any openEHR composition to any episode. This was needed because the legacy system we integrated with didn’t have versioning on such a change
Using folders - adding compositions to folders to make data belonging to the same context being placed in the same folder. As part of this we had to break the specification (at that time) which said that the EHR had only one root folder. This was not useful for our use-cases.
I agree the folder-approach seems to be the most useful and flexible. It also allows a simple way to retroactively include “micro visits” in a broader visit/episode without touching the (possibly already digitally signed) compositions (or the folder) from the “micro visit”.
Clarifying how to filter based on FOLDER in AQL is urgent. Perhaps @bna or somebody else can start a separate discourse thread on that.
Yes this is the tricky part when creating a new composition via API if the New composition-id is created by the server. Then you don’t know what composition id to refer to in the folder-update that you’d like to preform in the same Dingle contribution/transaction.
A possible solution might be to either have the client create the ID (and hope the client uuid generation mechanism avoids collitions) or to specify à New API call to first create/reserve a new unique ID that is then used in both the composition and in the composition reference/pointer of the folder.
In addition to that contribution-basen approach it could be handy to also add a new header or parameter to the “simplified” …/composition REST endpoint that allows you to specify a folder (or a list of folders) that you’d like the server to add this composition to. (The contribution stuff with composition creation and folder update would then be done “under the hood” in the server.)