Hi!
Recently in the specification #general Slack channel we have had some wild brainstorming and discussions ranging from improving to removing (deprecating) the openEHR demographic specifications
@sebastian.iancu reminded that slack discussions are less visible (and expire when we pass time thresholds) and suggested moving them to Discourse. I hope different voices in that discussion can contribute a compressed version of that discussion also here.
Background
@sebastian.iancu has started authoring a REST specification for accessing the classes in the demographic package so that they can be accessed in a standardized way. In earlier discussions it has been mentioned that demographics is not a perfect name for this if we want to expand it to more general resources like rooms, equipment etc.
Perhaps an improved version of this part of the RM can be thought of as a (version controlled) registry of information complementing the more encounter and episode-focused things that the EHR-part of the RM focuses on. If we are going that direction, then perhaps we could prefix the new REST services …/registry/… instead of …/demographic/…? Also in the work with an openEHR URN syntax it would be good to set a more extendible future proof ‘registry’ syntax rather than ‘demographic’ for the parts that don’t fit under the EHR object.
Current draft suggestion (initial brainstorm)
Here is a current model suggestion sketch created by @thomas.beale
summarizing part of the Slack discussion (from those that don’t want to deprecate the demographics part). It includes the ACCOUNTABILITY part discussed in the previous post above. Please mentally remove the “2” in the class names below, it was added to avoid naming collisions in a modelling tool.
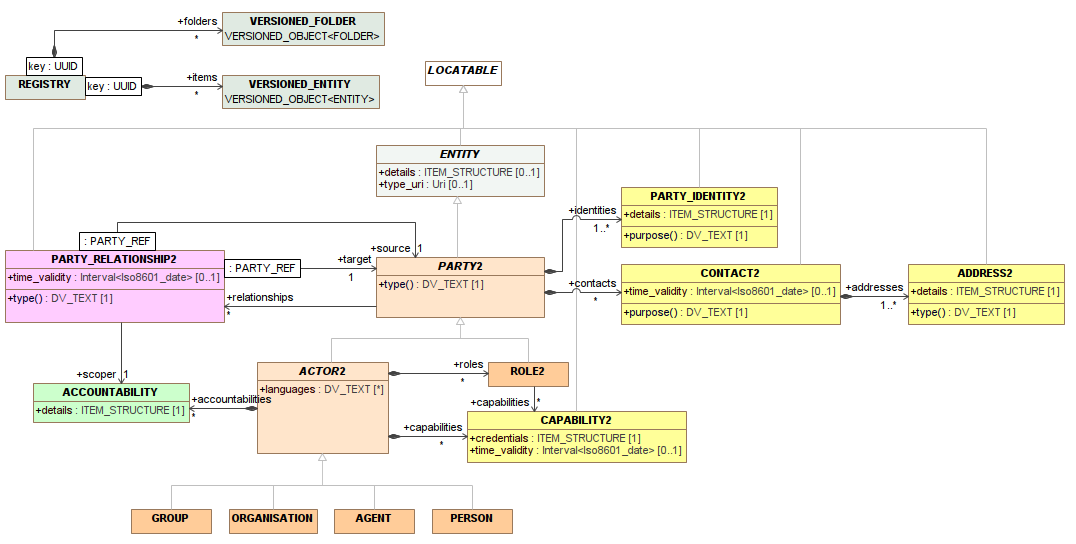
The main changes are new ENTITY, ACCOUNTABILITY and REGISTRY classes. The ENTITY class is on purpose very general to allow storing various things in the registry. The inheritance from LOCATABLE and the ‘details’ ITEM_STRUCTURE property makes it archetypable. LOCATABLE also allows for LINKs between registry objects (and potentially EHR content). The type_uri can be used for marking semantic types using ontologies or other URI-identifiable models like HL7 FHIR resources.
TODO: Discuss if the ENTITY class should be abstract and have a lot of subclasses (a mix of abstract and concrete) or be concrete and then use archetyping and (possibly improved) LINKs to represent things like devices and facilities.
There were more thoughts in the discussion that hopefully will show up in a continued discussion here. What are your thoughts? Should the demographic model be deprecated, unchanged or changed to ar more general registry? Why?