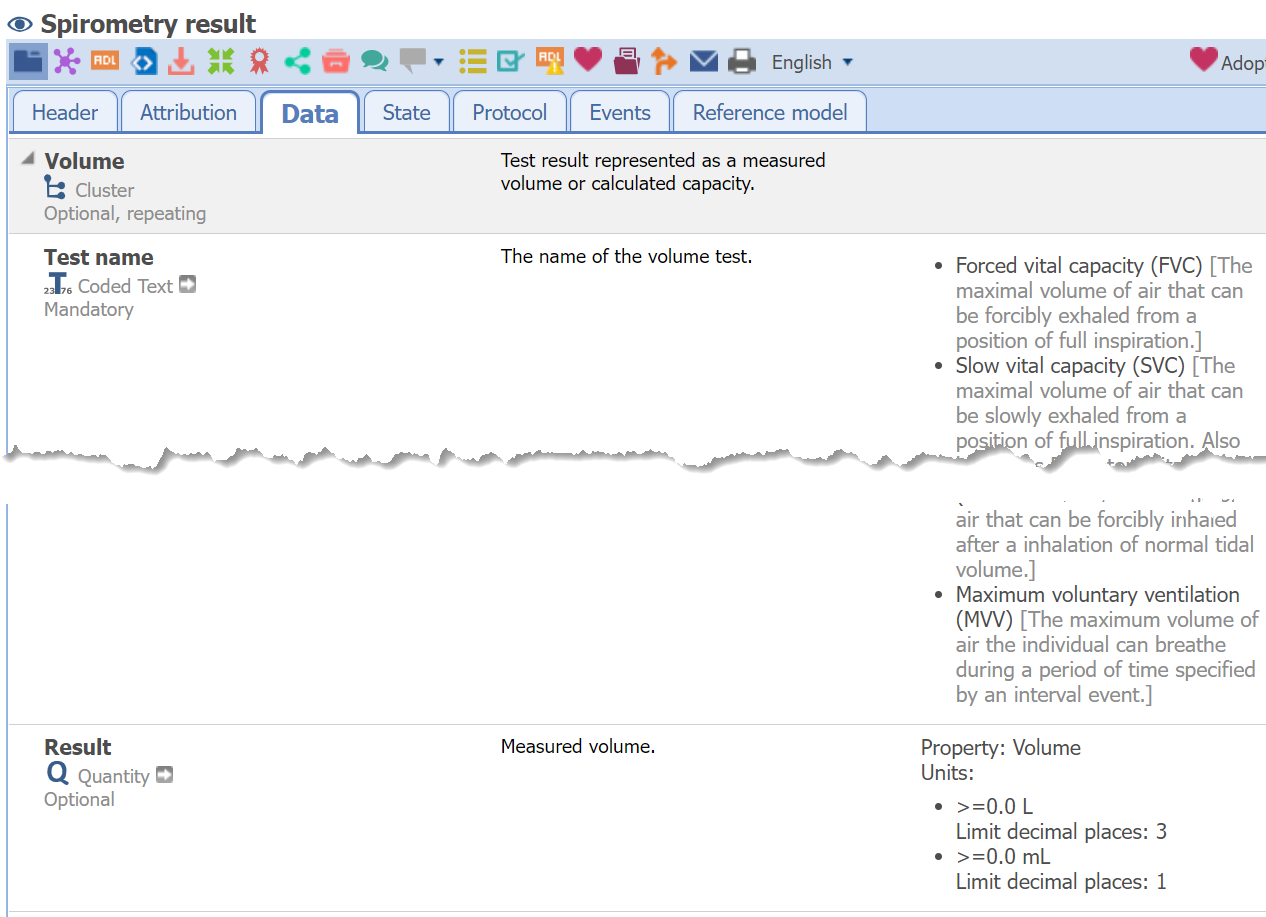
Respectfully, are you sure this can’t be done with ADL1.4?
I’ve tried hacking a test archetype like this:
events cardinality matches {1..*; unordered} matches {
EVENT[at0002] occurrences matches {0..*} matches { -- Any event
name matches {
DV_CODED_TEXT matches {
defining_code matches {
[SNOMED-CT::10987654321]
}
}
}
data matches {
ITEM_TREE[at0003] matches { -- Tree
…and it seems like it’s producing a perfectly valid OPT (I’ve removed all instances of <existence /> and <occurrences /> for readability):
<rm_type_name>EVENT</rm_type_name>
<node_id>at0002</node_id>
<attributes xsi:type="C_SINGLE_ATTRIBUTE">
<rm_attribute_name>name</rm_attribute_name>
<match_negated>false</match_negated>
<children xsi:type="C_COMPLEX_OBJECT">
<rm_type_name>DV_CODED_TEXT</rm_type_name>
<node_id></node_id>
<attributes xsi:type="C_SINGLE_ATTRIBUTE">
<rm_attribute_name>defining_code</rm_attribute_name>
<match_negated>false</match_negated>
<children xsi:type="C_CODE_PHRASE">
<rm_type_name>CODE_PHRASE</rm_type_name>
<node_id></node_id>
<terminology_id>
<value>SNOMED-CT</value>
</terminology_id>
<code_list>10987654321</code_list>
</children>
</attributes>
</children>
</attributes>
This also works if I use an archetype with the element name unconstrained, and hack the template instead:
ELEMENT[at0004] occurrences matches {0..1} matches { -- DV_TEXT
value matches {
DV_TEXT matches {*}
}
}
{
"@type" : "C_COMPLEX_OBJECT",
"rmTypeName" : "ELEMENT",
"occurrences" : "0..1",
"nodeId" : "at0004.1",
"attributes" : [
{
"@type": "C_ATTRIBUTE",
"rmAttributeName": "name",
"children": [
{
"@type": "C_COMPLEX_OBJECT",
"rmTypeName": "DV_CODED_TEXT",
"attributes": [
{
"@type": "C_ATTRIBUTE",
"rmAttributeName": "defining_code",
"children": [
{
"@type": "C_TERMINOLOGY_CODE",
"rmTypeName": "TERMINOLOGY_CODE",
"occurrences": "1..1",
"terminologyId": {
"value": "SNOMED-CT"
},
"constraint": [
"10987654321"
],
"selectedTerminologies": []
}
]
}
],
"attributeTuples": []
}
]
}
}
<node_id>at0004</node_id>
<attributes xsi:type="C_SINGLE_ATTRIBUTE">
<rm_attribute_name>name</rm_attribute_name>
<match_negated>false</match_negated>
<children xsi:type="C_COMPLEX_OBJECT">
<rm_type_name>DV_CODED_TEXT</rm_type_name>
<node_id></node_id>
<attributes xsi:type="C_SINGLE_ATTRIBUTE">
<rm_attribute_name>defining_code</rm_attribute_name>
<match_negated>false</match_negated>
<children xsi:type="C_CODE_PHRASE">
<rm_type_name>CODE_PHRASE</rm_type_name>
<node_id></node_id>
<terminology_id>
<value>SNOMED-CT</value>
</terminology_id>
<code_list>10987654321</code_list>
</children>
</attributes>
</children>
</attributes>