Something like the second suggestion in that post pretty closely simulates the bindings + symbolic approach I have advocated. It means that the rules are readable, which I think helps a lot.
A for_all and perhaps an exists block, rather than a for_all just in a statement, in which one can define variables as pointing to a path, would result in a small modification to the current grammar resulting in much more easy to read rules. Then rules could be written so that paths appear only in binding to variables, and assertions can be written only with variables, and nearly all variables could point to single values instead of lists or other collections. Without any complex ‘operators have to be defined on lists as well as single values’ logic, as we currently have.
However, if data binding is made separate from the language, and you cannot use a path anywhere else in the language, this will complicate these issues very much - then you cannot easily express ‘I want these rules to apply to this event in this observation only, even if the event occurs multiple times, but I still want to reference other data in the observation outside of the single event’.
if data binding is separate, but sub-paths are still possible, and a for_all block is added, then the problem is also easily solved.
Wouldn’t you just create a more specific binding for that particular event, to a more specific variable, e.g. ‘Apgar_heartrate_5_mins’ or similar, when you might already have ‘Apgar_heartrate’? Or you are talking about apply these rules in the sub-tree at this path? For the latter I think you would define a binding to the container object (HISTORY or whatever) under which you want a for_all or there_exists to execute.
It’s an interesting question generally as to whether the binding needs to be separate from the language. I have made the assumption that it does because the bindings in GDL, Task Planning and Archetypes are all completely different.
I am more inclined to this approach - because with only symbolic vars in the EL, EL texts are least is readable and maintainable. This goes back to our discussion last year.
I had another thought on this - I just realised you probably thought that I propose no path access method at all within a revised EL. The approach I propose is more like Xpath. Firstly it is access to nodes below some root object within data, i.e. instance level paths. In Xpath, as we all know, this is done with predicates in . And predicates can be (nearly) any expression to get to the intended sub-node, including path-patterns, but also other expressions, e.g. the simple ones like [1] (the first item). If we treat an inline archetype path as a path pattern predicate we then achieve what you want (which I agree with of course ![]() - but the semantics are now clearer - they are as in Xpath - if the path pattern matches 10 real paths in the current data instance, then that’s what you get.
- but the semantics are now clearer - they are as in Xpath - if the path pattern matches 10 real paths in the current data instance, then that’s what you get.
The new proposed EL has this kind of functionality, see here (but no path example there yet).
The paths by the way would have ‘.’ separators rather than ‘/’, indicating formal RM structure access.
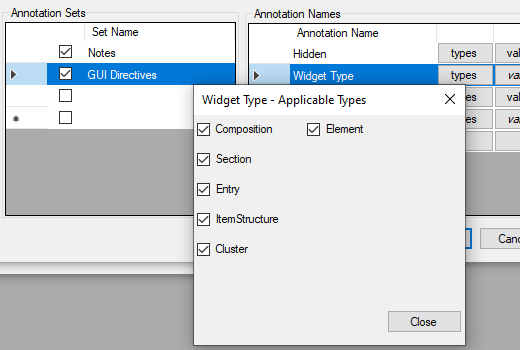
A side note: In Ocean Template designer 3.1 (from 2015?) you can add configuration of annotation types (in subcatefories called sets), and say what elements they apply to, and optionally what the allowed values are. As default on installation the Categories “Notes” and “GUI directives” are included, see screenshot.
Does anybody remember what the “Group” annotation was intended for?
Also, when trying to load templates with “plain” annotation names (like “fhir_mapping”) the tool gives an error. So the annotation names have to be changed to be in a prefix.suffix format. (I assume that is to cater for the annotation sets.
Prefixing the experimental annotations discussed in this thread may be a good thing anyway.
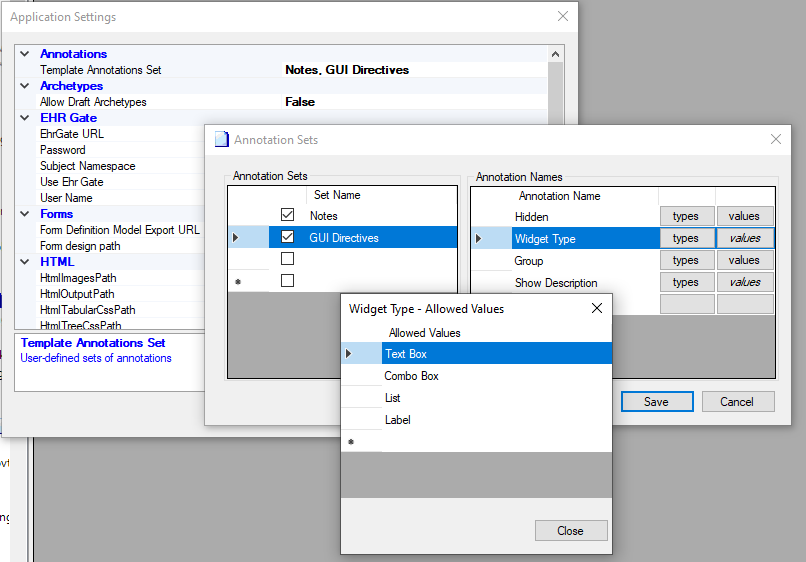
I don’t know, but assume that Group may be a hint that several elements belong together in some way.
Not sure this part was ever used much though.
There is also a newer more advanced Annotation Designer in Template Designer nowadays, but independent of that I believe that the annotations were extended so that simple keys like fhir_mapping can be used (or at least read) as well without a prefix in the latest version.
Maybe it is the ‘group’ constraint described here.
ADL 2/OPT 2 annotations have the same concept, called groups, although in the specification currently only ‘documentation’ is defined. See Archetype Definition Language 2 (ADL2) .
@thomas.beale the RESOURCE_ANNOTATIONS class in the resource specification seems to have disappeared in the latest specification.
I think with the current ADL 2 rules, plus a well defined set of annotations, it is possible to create interactive templates with quite a lot of user interface hints. Rules and annotations have a different purpose here: rules can be used for extended validations and interactive forms. Annotations can be used to define user interface hints, such as which UI element should be rendered. That means one is not an easy replacement for the other.
Agree - although annotations get used for other things unrelated to UI as well including pure documentation.
Yes, thanks. But the definition of the RESOURCE_ANNOTATIONS class is missing from that specification.
Ah - I see a class include is missing from the spec - it’s in the UML diagram. I’ll fix that.
EDIT: Fixed now in latest version.
1 Like
@thomas.beale regarding an elsewhere mentioned idea of a possible “ADL3” serialisation/variant of ADL2 semantics, perhaps something like the above mentioned…

…could be used to have consistent mapping between at/id codes of nodes and “readable” IDs?
I think that is a good idea. Such an annotation - or feature, if ADL 3 - could also be very useful for stable developer friendly ‘simple’ API generation, that remains the same even if the archetype gets textual changes. Which as far as I know is not really the case for the current json web templates plus APIs that often appear to be used. Also it could improve the field names in generated APIs.
It makes it more complicated to design archetypes though, unless these values can be auto-generated from the textual descriptions. Now clinicians without technical experience can design archetypes, you may need a more technical person to design and maintain sensible textual ids. The improved developer-friendlyness could very well be worth it…
1 Like
I need a little help to understand the impact for clinical modellers. If something is very valuable for developers, that usually translates to value for users. So it may well be worth it indeed. But we need to check wether it’s possible for (current) modellers to perform this job. And to think of ways to help them if we agree the value is there.
Could you give an example of what I would have to do differently for a specific archetype/template please?
@joostholslag I think this area shouldn’t be mixed with clinical modeling at all, IMHO this goes in a different semantic layer, so developers can add what they need to display data on top of the template, so clinical modelers are not affected by these extra things.
If a specific company wants to extend what templates can do, that’s OK, though that extension won’t be standard, so don’t expect portability of those artifacts. But if we separate visual stuff from clinical models, we can keep artifacts compatible between vendors, clinical modelers unaffected and developers can do what they need. Then we can standardize that new layer with metadata for visual artifacts.
This opinion is not shared by many here, I just don’t like to mix things and to apply the Separation of Concerns concept to our models.
1 Like
While I broadly agree, Pablo, as a clinical modeller, I do often have to communicate information to developers which are a little broader than just the current template content e.g use of RM attributes, data conditionality, use of local aliases for term lists etc. which is really part of the semantic layer and not user-interface directions as such. This is very much part of what I would regard as the in the scope of the ‘clinical modeller’, especially when working with non-specialist developers.
However, I still think this is a better handled as a separate path-based layer over the top of templates and not part of the current template scope.
this, and I historically broadly had the side of @pablo on this one ![]() Formal downstream artefacts is potentially the direction with the most ROI for openEHR specs to go at the moment. Recent OMOP presentation and implementation from @SevKohler is just another example of it.
Formal downstream artefacts is potentially the direction with the most ROI for openEHR specs to go at the moment. Recent OMOP presentation and implementation from @SevKohler is just another example of it.
1 Like
In archetypes usually nothing.
When it comes to many templates a use case is often known and the things expressible in ADL rules would be good to have an equivalent workaround for, as shown in examples in this thread, using template annotations until all major template- and form-building tools support ADL rules. Things like if user responded yes to X then show Y. These are things that the template modeller nowadays instead have to pass down to form develpers in separate non standardised documentation and such show/hide logic then needs to be recreated in several different vendors systems (up to three times in our current case).Those working in a monoculture of only one vendor’s system stack or that always have the same persons/teams deveoping both template and form may never understand this problem/need and will keep saying it should only be done in a separate vendor specific layer.
Also an annotation like “a.hide_on_form” would be very useful. Look at the “Screening purpose” and “Symptom/sign name” in the “Symptom/sign screening questionnaire” archetype for example. In a template we usually set them to default fixed values that should not be shown to patients filling out the form.
An annotation like “a.id” for giving a short meaningful id to a node would be good to make rules refering to it more readable (as suggested by @thomas.beale and @pieterbos above).
Well, in ADL2 I believe a specialised template (potentially containing only the discussed extra annotations) would be exactly a separate path based layer on top of another “pure” (non-annotated) tempate.
In ADL/OET/OPT 1.4 I guess a template copy with added annotations would work in a similar way (but needs more disciplined refactoring of two files when changed)
So there is no need to invent another formalism/format for the main things discussed in this thread - annotations (and, if anyone so wishes, another template layer via specialisation or copy) would do the trick.