Ideally, in AQL we would use CONTAINS wherever logical containment is understood in the relevant RM. Logical containment means deletion semantics, i.e. cascaded-delete in RBMS thinking. Now in the openEHR RM, if we do a DELETE on an EHR, we would logically cascade that DELETE through to all referenced FOLDERs, COMPOSITIONs, EHR_STATUS and so on.
To specify that formally would require a kind of reference type that can be marked as ‘composition’ or ‘association’, in the same way UML does for direct association refs between objects (i.e. black diamond versus no diamond). But for concrete types that are intended to be physical references to sub-parts, for reasons of computational convenience or whatever, there is no way in UML or BMM to directly mark them as being composition or association.
I have implemented ‘smart references’ in the past (probably we all did at some point) that have this knowledge in them, but of course its just a specific class, it’s not built in to the language. We could take that path in openEHR RM: add a data element to the XXX_REF types that mark them as composition or association, or subtype them.
Doing it properly means putting it in the BMM, where you could look up EHR.compositions and discover that the logical relationship between the EHR and the target objects of the references (COMPOSITIONs etc) was indeed composition (or not). With that info, CONTAINS in an AQL query could be correctly interpreted for both EHR[x] CONTAINS COMPOSITION[arch-id] and COMPOSITION CONTAINS CLUSTER.
This is something I have been thinking about, and indeed, it would be easy to specify and add to the current BMM schemas. If AQL processors were to use the Archie BMM lib to read the BMMs, then the info would be right there, and everything falls into place.
is that implicitly not the ‘type’ attribute of the OBJECT_REF?
About CONTAINS:
This is a key aspect that has to be clear from AQL spec about CONTAINS. Perhaps it deserves a small chapter.
If we all accept this as “design pattern”, then perhaps we don’t need (now) to further engineer this (with the BMM thing above)?! But, on the other hand it might be useful to have it, if AQL processor would use BMMs.
I don’t feel this explanations makes it better. The “universe” term is (in my opinion) not very appropriate here, and also putting there the CDR would restrain in the scope to only EHR, whereas as I mentioned earlier, I really would like to consider also DEMOGRAPHIC domain for AQL.
As inspiration, I kind of like the simplicity of how wikipedia defines FROM (see From (SQL) - Wikipedia ), “… will provide the rowset to be exposed through a [Select] statement”. Perhaps @Seref will find a way of simplifying his original text there, using less (openEHR) words, and keeping CONTAINS explanation for a separate chapter?
Agree on that - AQL itself doesn’t know anything about ‘CDRs’, ‘EHRs’ or any other specific kind of data.
I suppose concretely FROM specifies a ‘row-set’, but really it specifies the ‘database’, in the abstract sense, which is essentially the ‘universe’ of data to which the query applies. This is also sometimes called a ‘schema’, which is a DB word meaning ‘model’.
I’d rather keep it as it is, happy to hear suggestions that give the same meaning.
Thx, reworded that part
Nope
Yep, done.
removed it, because it actually does not define the scope. It defines the source, and scope is defined by SELECT and WHERE potentially extending and narrowing based on the source/root.
I don’t think so. A formal definition is what was requested and IMHO a formal definition should not start with an example. The bits you expand on are the rest of the section for FROM. What I’ve written above is just the introduction based on the definition.
I respectfully, but strongly disagree I’ve seen this point made before and I meant to respond then. AQL has the potential to be generic query language to query any underlying model but I’m in favour of defining it strictly based on openEHR terms, based on openEHR EHRs, data types, structures etc.
With my implementer hat on, I would like a query language spec to focus on the language and terms of data that I’m processing. This is why my suggestions for a formal definition of FROM above refer to RM types, their attributes, containment in EHR etc.
I am the one who raised the overloaded semantics of CONTAINS and I’m happy to further specify it but I would rather do that based on more openEHR words, not less.
I made a second pass to simplify my definition but I’m keen to address potential adapters using an openEHR specific terminology and language.
That’s my 2 pennies of course, happy to hear what @bna and @matijap would think.
I agree on this. We need a query language which fits the RM as good as possible. My experience so far is that the match could have been better. Data defined by our RM is hierarchical like trees, and with the possibility of making references it goes into a multi hierarchical graph. This is when you get challenges with todays AQL. It, kind of, assumes a flat database scheme and a flat tabular row based resultset.
I think current AQL is really good for lots of use cases. And I will not be surprised if we some day made a new specification which covered the hierarchical data better.
This could happen through revolution or evolution. Anyway it has to be a domain specific language for the EHR.
Well, query language semantics should not differ across data models the language processes. The optimisations that might be possible are another thing. If I were implementing an AQL engine, I would expect to have some bags of heuristic rules for processing queries against particular RMs in particular usages, e.g. openEHR RM in EHRs; openEHR RM in HighMed research; openEHR demographics in an MPI; openEHR Task Planning data.
But I can’t see how the formal language specification can have anything in it that is specific to any particular model. Indeed, I am not aware of anything in the current grammar that is specific to the openEHR RM.
There is also the question of ‘clinical safety’ as Ian as raised in the past. Whether some other layer(s) of semantics are needed over the top of AQL in particular contexts is something to explore as well. But again, if such layers can’t rely on general query language semantics, you’d never be able to write those other layers.
The CONTAINS semantics can be quite easily specified in the BMM (or other representation) of any model; right now they are not, and so, AQL engines/services don’t know that logically, an openEHR EHR object ‘contains’ (= has sub-part) COMPOSITION, FOLDER, EHR_STATUS etc. We need to fix that. But building it in to the language itself is not the correct approach - it has to be stated in the model definition semantics, and we can do that, indeed, it would not be hard to add it to today’s BMMs with a small amount of work. Tools like the Better ADL-designer already read BMM files; in future AQL processors can as well, and all will be well with CONTAINS.
I agree, but I also cannot see how I may have suggested that. We have one data model as far I’m concerned: openEHR RM and data based on instances of RM.
Maybe I’m missing something here but these are all RM implementations, based on the single RM specification. I cannot see why they would be called ‘particular RMs’.
There is more than one way to skin a cat when it comes to formalising something. I’m in favour of formalising AQL on top of RM. It could also be formalised based on BMM, Tree Pattern Queries as I mentioned above, or with some other, well… formalism My understanding of formalising is ‘specifying its behaviour’ and I suggest we do that based on references to data defined by the RM, which consequently implies using the concepts and terms of the RM, as in, “FROM clause defines data elements based on RM types and constraints on RM type attributes …” etc.
I am concerned about having to resort to other and especially more generic formalisms to define/formalise AQL unless there is no way to do this without using the RM subset of openEHR specifications. The execution semantics is one example of RM not being sufficient, where I suggested the use of TPQ or alternatives, but as I said to @sebastian.iancu above, I’d still try to see that more in the ITS space and not in the AQL specification.
Well, grammar is at syntax/lexical level and even there you’d have things specific to openEHR if we wanted to help implementers, for example, you cannot have an archetype id token in an AQL query that would not be valid archetype id identifier according to RM, as in ... COMPOSITION c[myLovelyComp]... should not even be syntactically valid because we define valid archetype ID syntax in the RM
My points above re the semantics of CONTAINS are explained in terms of RM as you can see, I don’t need to break the self-containment of RM spec to explain CONTAINS can mean both resolving an aggregation relationship and a composition one. I’m merely suggesting we follow that approach.
completely agree, but your comment seems to imply you don’t think we can specify query language semantics without using another formalism. I’d say query semantics can be specified within RM, but execution is different and even than that’s ITS.
They do. The fact that we have > 1 working implementations of AQL proves that they do BMM is another way for them to know it, but then again, we’re in the ITS space.
Are you suggesting we state query related aspects in the RM? Isn’t that what you and I consistently argued against so far, especially in case of GUI aspects, and most recently in Birger’s EHR subject concern?
I’m advocating we define what AQL does based on the RM specification, and how it may do it in the ITS, whether BMM or some other mechanism.
My attempt to follow the approach I’m suggesting is above. Maybe I’m failing to understand your suggestion and I’d be delighted to be corrected or shown the error of my ways because this stuff is bloody complicated!
Maybe I was not clear by what I meant when I said ‘BMM’ - I don’t mean the BMM formalism, I mean actual BMM instances, i.e. model definitions. We already have BMMs for the whole of openEHR, right here. These are the files that are consumed by tools that require a model definition.
I also have BMMs for FHIR and can make one for any model in the world. We can do the same thing with some other meta-formalism, like XMI or (maybe) JSON-schema, or whatever; we just use BMM because it works and fixes a whole lot of problems of XMI.
So what I am advocating re: specifying logical whole/part relationships, is that this semantic be defined in the BMM. (It is already in the latest BMM spec, just not in the implementations.)
If we specify this kind of thing properly in the BMM for any concrete model, then an AQL processor always processes the CONTAINS statement correctly.
Currently, AQL implementations (quite reasonably) are hard-wired to the openEHR RM, in the same way CKM is, and ADL workbench once was. We need to move AQL (and CKM) to being model-driven, and define the model-specific semantics in the model definition (BMM files, or XMI, or whatever else takes your fancy), and define the query specific semantics in the query language.
Thank you, this is indeed helpful. Allow me to allow you to help me further
a) I just cannot see what is wrong here.
b) How can anything be hard wired to RM when RM itself is technology agnostic?
I have no objections to validity of this approach, but I’m concerned about its consequences, because unless I’m missing something, this makes BMM implementation a precondition for AQL implementation. The downsides of which to me would be:
The learning curve for potential openEHR implementers, who now also have to understand BMM to understand AQL
The increase in implementation costs for potential and existing implementers.
I guess you can help me a lot more if you could tell me why defining AQL based on RM is bad (in the way you describe as hard wired)
Well, the openEHR RM, at the end of the day, is just a model of data. Naturally some of us think its quite good, but that’s subjective
The openEHR Demographics part of the RM is separate in the sense of not being part of the EHR, but really querying should work with it as well.
The point for a query language isn’t to be technology agnostic, the point is to be model-agnostic.
If we make it specific to some model, we have to specify something different / new just to say how AQL works for openEHR Demographics, Task Planning, or indeed, any archetyped data - including in other domains.
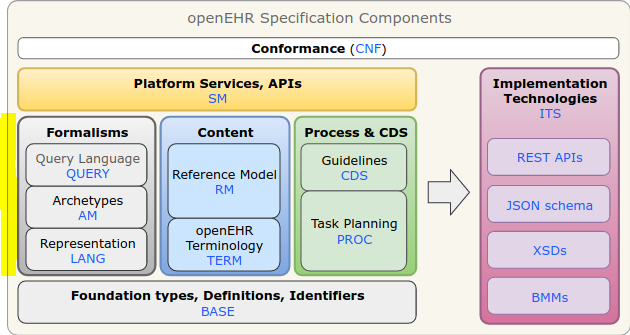
The one thing AQL does need to know about that is ‘openEHR-ish’ is of course Archetypes, archetype ids etc. But that’s part of the formalism layer of openEHR, not any of the models. Hence the most recent arrangement of the components into groups that follow this idea:
Re learning curve:
well we are talking about a small number of people who are all engineers and/or scientists, so I don’t think BMM will be much of a challenge. Mainly they will experience it just by using Archie, which will make it easy to use.
model-driven is the future. If it’s not BMM, it will be Ecore, son-of-UML (SysML2 maybe) or something else. We just don’t use those things today because they are out of date (no functional stuff), broken (generics, property/association semantics) and impossible to read, in the case of XMI.
Better’s ADL-designer already uses BMM to know about models; LinkEHR also reads them. Nedap’s nascent ADL tool is BMM-driven. HL7 CIMI is (or at least was until recently) using BMM. CKM will go there at some point…
I guess that depends on the definition of “scope” and “source”.
As I understand it, “source” would be “all your data” (the think I called universe because of the mathematical set theory term, which is the “given situation” or “given state”, that could also be “domain”).
Then “scope” would be the subset of the universe that you want to focus on (still thinking as set theory here).
The SELECT is to map a projection, I like these definitions:
" In relational algebra, a projection is a unary operation written as Π a 1 , . . . , a n ( R ) {\displaystyle \Pi {a{1},…,a_{n}}(R)} where a 1 , . . . , a n {\displaystyle a_{1},…,a_{n}} is a set of attribute names. The result of such projection is defined as the set obtained when the components of the tuple R {\displaystyle R} are restricted to the set { a 1 , . . . , a n } {\displaystyle {a_{1},…,a_{n}}} – it discards (or excludes ) the other attributes.[1]"
" Projection is one of the basic operations of Relational Algebra. It takes a relation and a (possibly empty) list of attributes of that relation as input. It outputs a relation containing only the specified list of attributes with duplicate tuples removed . In other words the output must also be a relation."
And the WHERE is for filtering data from the scope, only the data that passes the filters will appear in the projection.
I know everyone here might have their own definition or idea of things. Maybe we need to go down to the basic definitions that we will agree on, because we might be talking about different things. Of course, it depends on how strict or “mathematically correct” do we want to be on the spec. It’s also valid to define our own terms in the context of openEHR, but we need to have good definitions to avoid interpretation issues.
I agree, I shouldn’t mention CDR, I was thinking of data storage.
And I agree we should explicitly say AQL expressions could be used to query any archetype RM, including openEHR EHR and DEMOGRAPHIC, but could be used for other RMs. Also that should be extended to the examples, which are all focused on EHR.
I’m not sure about using the word ‘scope’ w.r.t. SQL or AQL. In simple terms, the various bits are as follows:
SELECT
projection (= subset of columns of a Table or View, or properties of a class/type)
FROM
domain / universe (= tables or classes/types from which columns/properties projection is defined)
WHERE
criteria (= row selection, by filtering on values)
That seams reasonable @thomas.beale, but interms of:
If we think of functions, FROM could be a function, the source data set for that function, could be EHR/DEMOGRAPHIC/xxx, is the domain (of that function), then the result or co-domain of the FROM applied to the domain is the domain for the query as a whole, since the query could also be considered a function.
But you can consider the query as a whole is applied to EHR/DEMOGRAPHIC/xxx, so that would be the domain for the query, not the result of the FROM, since the query would be a combination of functions applied one to the result of the other: QUERY_RESULT = SELECT(WHERE(FROM(domain))).
The difference is subtle, but really depends on what you are focusing on, the FROM clause or the complete AQL.
Even more, SELECT and WHERE are also functions, WHERE is a boolean function and SELECT is a mapping function. I would say FROM is a sub-set definition function (could be a “selection” function but gets weird having the SELECT clause).
This is what I understand it, I’m not saying this is the most correct way of understanding or defining things.
DIPS found a need to expand the query model to be able to run the same functional AQL with different constraints. This was suggested into the openEHR REST API v1.0. Since the SEC group wanted to keep the first version minimal this feature was postponed to later versions. We use the following request model. The tagScope and partitionBy is used a lot in production. The use-case is ward lists to query i.e. the latest (partitionBy = EpisodeOfCareId) body temperature for each episode of care (tag = EpisodeOfCareId).
Quite a lot of things were said here that, at least in my opinion, I think are important:
Well, I don’t know how others are fully understanding and deeply seeing and feeling all the aspect of above quote, but for me:
I get @thomas.beale advocating for formal description in a BMM, it is perhaps the right place
but I also agree @Seref about extra burden on depending on BMM
the whole discussion is around AQL processor and AQL formalism specification, to make it model-agnostic, but the data-storage is not formally specified (neither db-type, neither data-definition or structure), which (I guess) means that the AQL-execution itself is implementation-specific - I wonder how much (if any) the BMM can be used at that level, I have impression that is hard-wired (as opposed to ADL parsing which takes directly benefit of BMM).
I suggest adding an extra chapter or few paragraphs in the beginning of AQL specs, that will capture these conceptual design aspects in a dialog above between @thomas.beale and @Seref . It might be useful for implementors to better understand the necessity of BMM in relation with AQL.
but if we would like to use it in specs, then I would change it a bit:
SELECT
projection (= subset of columns or properties of the selected rowset)
FROM
domain (= rowset source, usually tables or classes/types from which columns/properties projection is defined)
WHERE
criteria (= rowset retrieval criteria, by filtering on their values)
Yep, this is also good, probably better. I wasn’t trying to provide a proper text BTW, just to state a sort of common sense understanding of these things, in the interests of not getting too complicated or academic. I leave it to the rest here to get the text right for the users of the AQL specification and tools.